
The new VMware Virtual SAN (or vSAN) 6.6 adds several enchaments and new features as described in the announce notes.
Most of those aspects are related to data and cluster resiliency (as expected by a storage solution), including:
- stretched clusters with local site protection
- new degraded device handling (DDH) feature that intelligently monitors the health of drives and proactively evacuates
- more intellingent rebuilds
- increase the availability of management tools so that clusters can be managed also when vCenter is down
The first one is probably one of the most important for data resiliency in a metro cluster: stretched cluster feature has already been proven in previous version, but now vSAN 6.6 provide both storage redundancy within a site AND across sites at the same time. Without the needs to change cluster configuration!
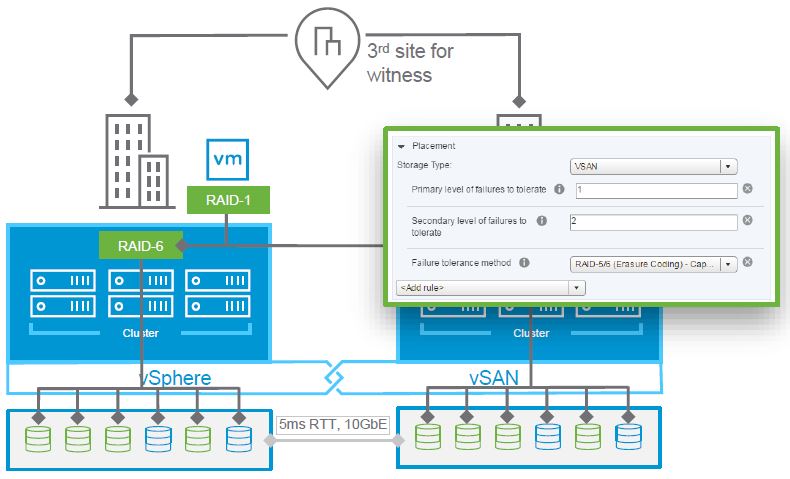
Now there are two different level of protection policies:
- Primary level of failures to tolerate (PFTT): that defines the cross site protection, usually implemented as RAID-1 (two copy of the data, one in each site).
- Secondary level of failures to tolerate (SFTT): that protect data resiliency inside a single site and can be implemented as RAID-1, RAID-5 or RAID-6.
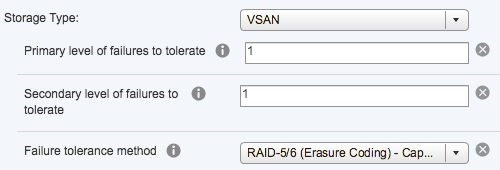
This helps deliver effective, affordable protection against entire site outages, as well as local outages within a site (that could be a host or also a single disk failure).
When using across sites and within site protection, data does not have to be fetched from the alternate site in the event of a host or disk failure, helping deliver greater performance along with the added layer of protection.
Actually secondary level of Failure To Tolerate only appears as a policy option when vSAN stretched cluster is enabled/configured.
But, in my opinion, this feature become relevant NOT only for metro-cluster, but also in a ROBO scenario in a two-nodes cluster where data resiliency was not strong in previous implementations: having only a network RAID1 it’s enough if hosts are fine, or if you have a single failure. But what about if you have a disk failure during a host maintenance? Or if you have two disks failure one on each host?
Maybe the second option could be rare, but the first one it’s a risk that you must consider. With this new option, I think that we will see this feature also ROBO in the the future and new reference architecture for ROBO scenario, where a second level of RAID5 can be used inside a node to provide local redoundancy and resiliency.
Also note the the witness for the cross-site protection must remain accessible (there must still be one data site and the witness site available): SFTT will not protect against the loss of a data site AND the loss of a witness.

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
