

This post is also available in: Inglese
Reading Time: 18 minutesQuesto è il secondo articolo di una serie realizzata per StarWind blog sul tema del design, pianificazione ed implementazione di un’infrastruttura per uno scenario ROBO. L’articolo originale (in inglese) è disponibile a questo link.
Design areas and technologies
Nel post precedente, abbiamo visto gli aspetti legati ai requisiti di business e i vincoli che si possono avere in uno scenario ROBO (Remote Offices / Branch Offices) tipico degli ambienti con più filiali. Il tutto tenendo conto anche dei possibili rischi che potrebbero impattare le diverse scelte.
Ora analizzeremo i requisiti e le possibili soluzioni dal punto di vista tecnologico cercando di considerare gli aspetti di:
- disponibilità (availability)
- gestibilità (manageability)
- prestazioni e scalabilità (performance)
- data e system protection (recoverability)
- sicurezza (security)
- risk management
Tutti questi aspetti devono poi essere calati sull’intera pila tecnologica, livello per livello, considerando:
- Workload e applicazioni
- Virtualizzazione e hypervisor
- Computing (CPU e RAM) e host fisico
- Storage
- Networking
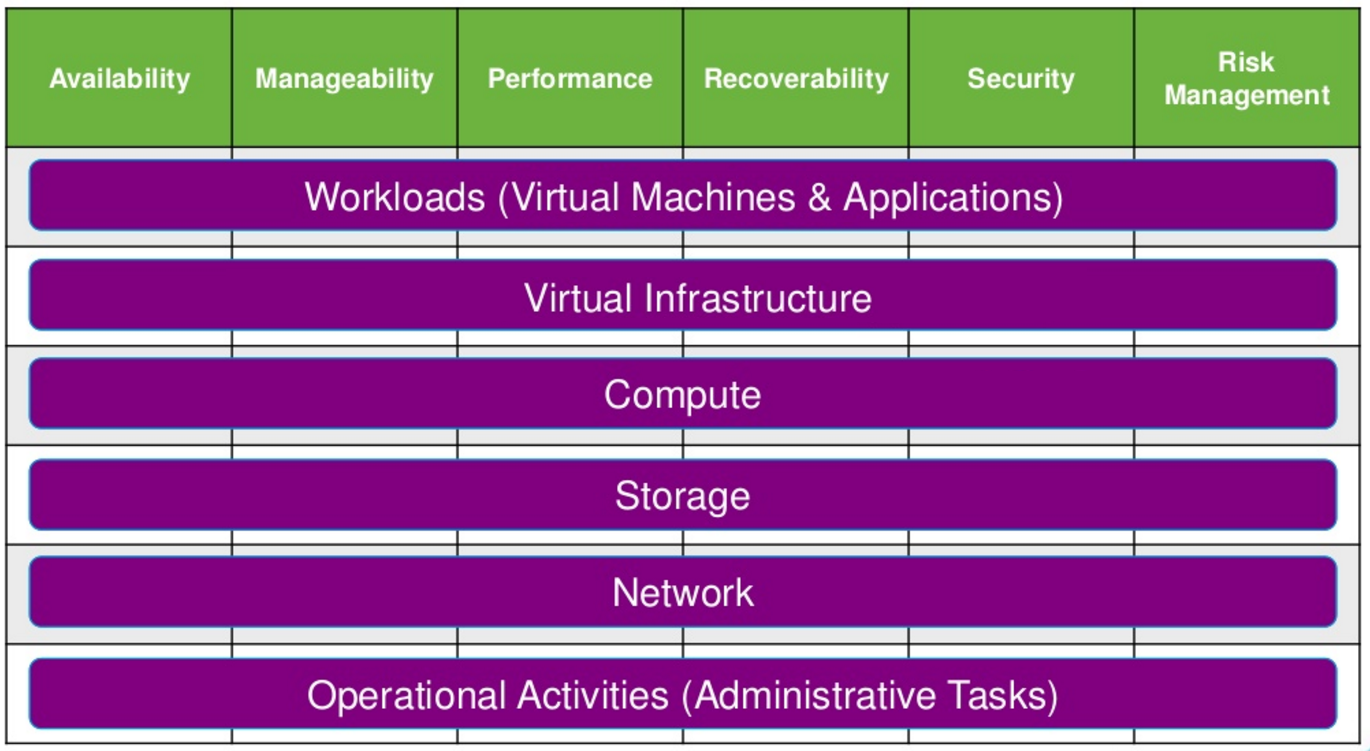
Disponibilità
Ovunque si parli di business la disponibilità è il principale aspetto da considerare, anche se può essere complicato stimare l’impatto della disponibilità sul business stesso e poter classificare alcuni workload come effettivamente business critical. In un ambiente ROBO si possono avere applicazioni in grado di fallire senza impattare direttamente sul business (ad esempio usando la sede centrale come fail-back), ma dipende dalle applicazioni e si possono avere molti casi dove invece l’infrastruttura di filiale può diventare critica da questo punto di vista. Chiaramente il tutto va mediato con i vincoli di budget.
La disponibilità di un sistema viene normalmente misurata in termini di numero di nove secondo questa tabella:
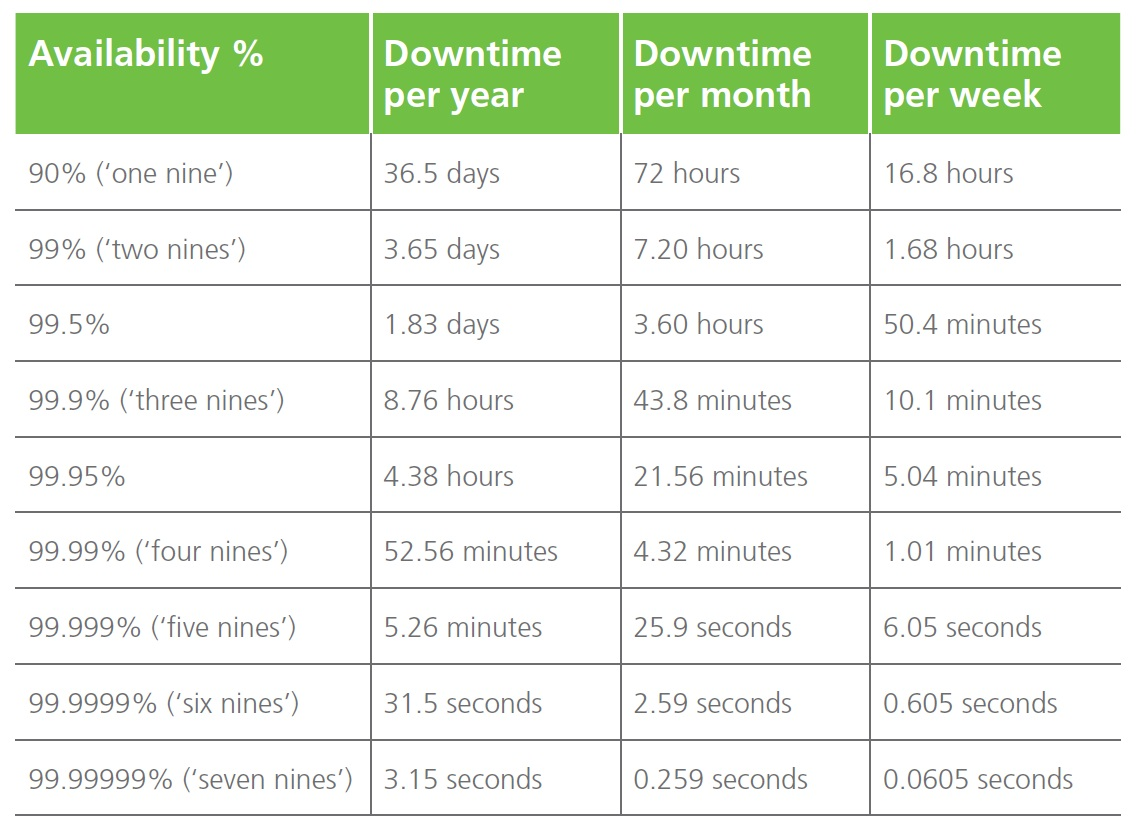
Anche se un ufficio remoto può essere piccolo come dimensione rispetto ad una realtà enterprise o corporate, i requisiti di business potrebbero (come già discusso) essere gli stessi e quindi anche i livelli di disponibilità richiesti potrebbero essere alti per alcuni servizi.
Potremmo avere requisiti che variano da 99% e 99,99%, ma anche maggiori in alcuni casi particolari per servizi molto critici. O persino requisiti più laschi per servizi che invece non sono affatto critici o che prevedono un fail-over automatico per un altro servizi (magari nella sede centrale).
Notare anche che si possono catalogare diverse categorie di disponibilità (con diversi costi ed impatti dal punto di vista di design):
- High availability: the service or application is available during specified operating hours with no (relevant) unplanned outages. Usually, ROBO falls in this one.
- Continuous operations: the service or application is available 24 hours a day, 7 days a week, with no scheduled outages.
- Continuous availability: the service or application is available 24 hours a day, 7 days a week, with no planned or unplanned outages.
Workload
Chiaramente i requisiti di business sono strettamente legati a come sono i vari workload e dal loro impatto in case di indisponibilità di un servizio
Ma come si può incrementare il livello di disponibilità di un servizio o di un’applicazione?
Se l’applicazione o il servizio sono già progettati per fallire ed essere altamente disponibili, allora la parte tecnologica sottostante può anche essere semplice e poter fallire a sua volta. L’impostante è progettare bene la distribuzione dei servizi, dove tipicamente ci sarà la sede centrale (o un altro punto) che sia in grado di sopperire alla mancanza di un servizio. Ovviamente questo non vuol dire che si può scegliere o progettare un’infrastruttura scadente, ma che il suo impatto non è così determinante.
Esempio di applicazioni di questo tipo sono il servizio DNS, l’Active Directory, Exchange con DAG, SQL Server on AlwaysOn. Alcune sono basate sul concetto di cluster applicativo, ma non sempre è determinante o necessario.
Viceversa, per applicazioni che non possono fallire, come la maggior parte delle applicazioni legacy, richiedono una struttura sottostante altamente affidabile o soluzioni di cluster applicativo di tipo HA.
Cluster high available
Un failover cluster è un gruppo (o cluster) di server (o nodi) che lavorano in ridondanza per garantire il funzionamento di un servizio anche a seguito del fallimento di un nodo. In questa eventualità un altro nodo prenderù in carico il servizio fallito e provvederà a riavviarlo correttamente (failover).
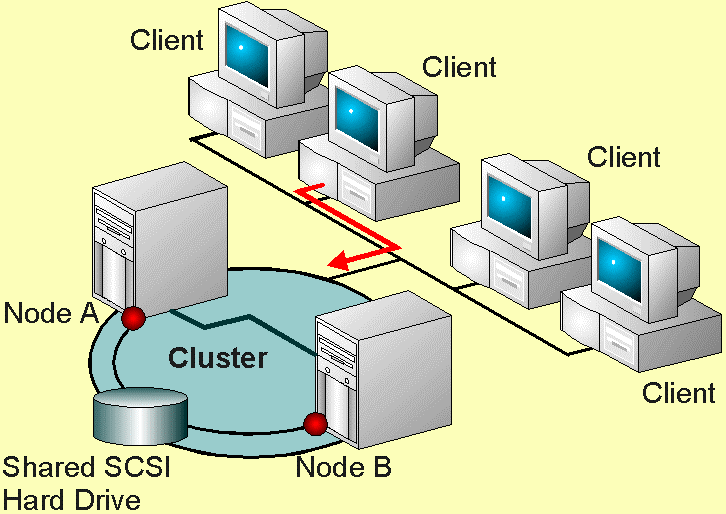
Vi sono diversi modi di implementare questo tipo di cluster, ma in Windows Server è inclusa la feature di Failover cluster, ma le applicazioni o i servizi devono essere compatibili con questa funzione, quindi è un approccio che non può essere sempre utilizzato (anche perché poi ha alcuni requisiti da soddisfare).
Notare che un approccio simile può essere utilizzato a livello di hpyervisor, dove il servizio è in realtà la macchina virtuale, in questo caso la soluzione è più generica e adatta alla maggior parte dei casi, ma fornisce anche un livello di disponibilità inferiore.
Virtualization
A seconda del tipo di hypervisor si possono avere diverse soluzioni, a questo livello, per aumentare la disponibilità dei livelli superiori.
In generale, ogn soluzione di virtualizzazione di classe enterprise fornisce almeno due tipi diversi di servizi basilari:
- VM HA: per riavviare le VM nel caso del fallimento dell’host sulle quali erano in esecuzione (secondo il concetto di cluster descritto in precedenza). Utiler per gli eventi di tipo non pianificato.
- VM live migration: per spostare le VM in esecuzione da un host ad un altro, senza interruzione. Utile per gli aventi pianificati o pianificabili.
Ovviamente va analizzato bene il tipo di failure che la soluzione di HA è in grado di gestire (ad esempio, gestisce il fallimento delal parte di storage?), come pure bisogna considerare che la virtualizzazione aggiunge altri elementi (ad esempio la parte di gestione) dei quali andrà poi valutata la relativa disponibilità e il livello desiderato/desiderabile.
Per VMware vSphere vi sono diverse soluzioni per incrementare la disponibilità, anche a seconda dell’edizione licenziata di ESXi:
- vSphere HA è la soluzione che gestisce il fallimento degli host (con alcuni limiti sul tipo di fallimento che è in grado di gestire) e riavvia le VM. Con la funzione di VM HA può anche gestire il fallimento del sistema operativo o (con software aggiuntivi) il fallimento delle applicazioni. Può garantire un livello di HA attorno al 99% (o qualcosa in più).
- VMware FT è simile alla precente soluzione, ma le VM non vengono riavviate, semplicemente continuano da dove erano arrivate. In questo modo è possibile fornire un elevato livello di HA (anche più del 99,99%), ma vi sono alcune limitazioni, non solo sulla licenza necessaria, ma sulla dimensione delle VM (grossi miglioramenti sono stati fatti in vSphere 6.0)
- VMware vMotion permette di spostare le VM tra un host e l’altro (al verificarsi di certi prerequisiti), persino tra due diversi vCenter (a partire da vSphere 6.0).
- VMware Storage vMotion è il duale della funzione precedente e permette di spostare VM tra due diversi storage o datastore.
Compute
A livello di host fisico si possono usare tutte le soluzioni possibili, come ottimi componenti, memorie affidabili (con ECC), parti ridondate (come ad esempio dischi in configurazione RAID e doppi alimentatori), ma vi saranno sempre dei single point of failure (SPOF) che ne minano il livello di disponibilità.
Per arrivare a livelli superiori del 99% bisogna per forza implementare una o più delle soluzioni precedenti. Di conseguenza, anche se in un ROBO probabilmente un server fisico potrebbe bastare (come potenza di calcolo), almeno due host sono ncessari per implementare soluzioni come, ad esempio, VMware HA. Più di due nodi, di solito, in uno scenario ROBO non sono necessari (anche per contenere i costi e gli spazi).
Storage
La parte di storage ovviamente deve avere ottima disponibilità (di solito si richiede almeno il 99,95%), ma soprattutto ottima affidabilità e protezione del dato. Se potrebbe essere accettabile non accedere ai dati per qualche minuto (o ora) è totalmente inaccettabile perdere i dati. Questo vuol dire non solo avere soluzioni di data protection (che considereremo successivamente), ma anche opportuna ridondanza per assicurarsi la massima resilienza del dato.
Lo storage può essere locale (o di tipo non condiviso, oppure in una soluzione iper-convergente), oppure esterno, ma spesso contano più aspetti di tipo economico. Vedremo in maggior dettaglio di possibili soluzioni di storage nei post seguenti.
Network
La rete in un ufficio remoto potrebbe non disporre della giusta ridondanza, e questo potrebbe essere un grande rischio per alcuni servizi (ad esempio nel caso la rete serva come back-end per una soluzione di storage replica, di storage iper-convergente o anche solo come rete di heartbeat per un cluster).
Spesso in uffici remoti si ha solo uno switch per tutta la rete (o pochi switch e non ridondati). In alcuni casi persino a soli 100 Mbps e generalmente tutt’altro che di tipo full rate.
Servizi che richiedono tanta banda e/o bassa latenza dovranno prevedere rete dedicata per minimizzare i rischi associati alla parte di infrastruttura di rete. In una soluzione a soli due nodi, è possibile considerare connessioni dirette senza l’uso di switch.
Recoverability
 Con questo termine ci riferiamo alla possibilità di ripristinare i servizi al punto nel quale sono stati interrotti (o ad un recovery point object prefissato). Benché questi aspetti sono parzialmente correlati con gli aspetti di disponibilità descritti in precedenza, più in generale si estendo a tutti i casi che l’HA non è in grado di gestire (ad esempio la perdita totale dello storage).
Con questo termine ci riferiamo alla possibilità di ripristinare i servizi al punto nel quale sono stati interrotti (o ad un recovery point object prefissato). Benché questi aspetti sono parzialmente correlati con gli aspetti di disponibilità descritti in precedenza, più in generale si estendo a tutti i casi che l’HA non è in grado di gestire (ad esempio la perdita totale dello storage).
Sono quindi più legati agli aspetti di business continuity e disaster recovery in quello che deve essere un quadro generale che includa ovviamente anche tutti gli aspetti di data e system protection (che discuteremo meglio in un post dedicato).
Gli aspetti di recoverability sono normalmente trasversali rispetto ai diversi layer tecnologici, visto che nel peggiore dei casi (disaster recovery di site) bisogna ripristinare tutto su uno stack completamente diverso.
Manageability
Dopo gli aspetti legati alla business continuity descritti nei punti precedenti, la gestibilità della soluzione è forse l’aspetto più importante per una realtà di tipo ROBO, dato che può impattare i costi operativi (o i relativi tempi).
Infatti, come già descritto, uno dei rischi connessi con le realtà ROBO è l’assenza (nella stragrande maggioranza dei casi) di team di supporto nelle filiali remote: sono le persone dell’IT centrale che devono gestire anche le filiali e, in caso di problemi non gestibili da remoto o attività in loco, che devono anche spostarsi.
Per questa ragione la gestione remota e possibilmente centralizzata è un must (in realtà non è detto che debba anche essere centralizzata, se si ha comunque una facilità d’uso adeguata). Per il monitoraggio è auspicabile un sistema centralizzato che sia in grado di ricapitolare la situazione in una o poche dashboard.
La gestione deve anche considerare la parte fisica, in particolare dei server (ad esempio tramite interfacce di management come le ILOE dei server HP o le iDRAC dei server Dell), ma anche di altri apparati in rete (tramite opportune interfacce di gestione out-of-band o tramite normale gestione remota). Per i server gestire da remoto la console, come pure l’accensione e lo spegnimento, può essere estremamente utile in caso di blocchi critici (ad esempio la schermata viola di ESXi) o anche solo per installazione / re installazione da remoto.
Notare che la possibilità di gestire il tutto da console o server centralizzati potrebbe essere fortemente penalizzata od impattata dalla disponibilità di banda e dalla latenza della connessione geografica. Discorso analogo si può fare per il monitoraggio, anche se normalmente è meno impattato da aspetti di latenza.
Prendendo come esempio VMware, la gestione avviene tipicamente tramite tramite vCenter e sono possibili diverse topologie in un caso ROBO:
si potrebbe realizzare con un singolo vCenter Server nella sede centrale, ma eventuali problemi di latenza causerebbero frequenti disconnessioni degli host.
- Single vCenter (centralizzato): ma in questo caso la banda può essere critica per avere una gestione fluida, ma ancora più critica è latenza e l’affidabilità della rete che possono causare continue disconnessioni degli host ESXi remoti.
- Più vCenter Server in Linked mode: in ogni filiale si potrebbe usare un vCenter collegato in “linked-mode” con gli altri. Questo garantirebbe una vista centralizzata. L’effetto di problemi di banda, latenza o perdita di pacchetti di rete verrebbe minimizzato.
- Più vCenter Server “stand-alone”: ogni filiale è un’isola a sé stante, con gestione separata.
Questi scenari vanno comunque analizzati considerando anche gli aspetti del licensing che possono limitare le scelte possibili: ad esempio solo i vCenter Standard si possono “linkare” tra di loro e un vCenter Standard non può gestire (a partire da vSphere 5.0) host ESXi con licenza Essential o Essential+. Ovviamente gli host ESXi free non possono essere gestiti da nessun vCenter.
Per il monitoraggio esistono invece molti tool in grado di aggregare informazioni anche da più vCenter (o persino host stand-alone) e mostrarli in un’unica dashboard. Incluse soluzioni OpenSource.
Per quanto riguarda i backup e la loro gestione centralizzata di rimanda ad un apposito post dedicato.
Performance and scaling
 Di solito le prestazioni non sono un problema nel caso di scenari ROBO. Anzi, in molti casi un host potrebbe reggere tutto il carico di una filiale, e quindi due (per una questione di alta disponibilità) sono in molti casi abbondanti.
Di solito le prestazioni non sono un problema nel caso di scenari ROBO. Anzi, in molti casi un host potrebbe reggere tutto il carico di una filiale, e quindi due (per una questione di alta disponibilità) sono in molti casi abbondanti.
Risulta più importante arrivare ad un modello e “template” per ogni filiale che possa facilmente essere replicato e scalato in tutte le filiali (o in quelle con esigenze simili), in modo da creare una reference architecture (o un building block) facilmente riciclabile.
Networking
Per la rete, come già discusso, è probabile trovarsi switch da 1 Gbps pensati per le PMI. Magari hanno porte di uplink a 10 Gbps ma sono normalmente inadatte per un host. Ma si potrebbero trovare persino switch a 100 Mbps!
In alcuni casi, come ad esempio con soluzioni iper-convergenti, i requisiti di banda, latenza e prestazioni potrebbero essere più stringenti, ma come già discusso per una soluzione a due nodi è pensabile di usare una coppia di schede per server collegate direttamente punto punto. In questo modo si minimizza il rischio di usare switch di fascia bassa o si limita il budget nel dover acquistare switch di fascia alta.
E per quanto riguarda la rete geogratica? Qual è la banda minima (rispetto alla sede principale) per una fililate? Dipende molto da tipo di gestione e dagli strumenti centralizzati che si voglio usare che potrebbero essere impattati da tipo di banda, ma anche dalla latenza e dall’affidabilità della linea.
In molti casi almeno 1 Mbps simmetrico potrebbe bastare (o essere un buon punto di partenza), con una latenza che possibilmente non superi le centinaia di millisecondi.
Storage
Parlando di prestazioni lo storage è tipicamente il primo problema o l’aspetto di critico da questo punto di vista. Ma negli scenari ROBO il numero di workload potrebbe essere molto limitato (a volte anche solo una coppia di VM) e quindi lo storage è meno critico.
Dischi di tipo flash potrebbero essere un’opzione possibile (magari come read cache), ma non necessaria, visto che in molti casi un disco rotativo (a 10K) potrebbe tranquillamente “sostenere” 2/3 VM medie con prestazioni accettabili.
Più importati sono gli aspetti di disponibilità e resilienza, come potrebbe essere importante (almeno per il design) il requisito di capacità.
Nel post successivo discuteremo di diverse possibili scelte nello storage.
Compute
In uno scenario ROBO scenario il processore (di solito) non è un limite, visto anche che i processori moderni hanno veramente tante risorse disponibili e in singolo socket è possibile avere tanti core (anche 12 ad un prezzo accessibile). Notare che il numero di socket può incidere sul costo di alcune licenze, come pure per Windows Server 2016 il numero di core può incidere sul numero di licenze richieste (vedere questo post).
Più critica può risulta la RAM che potrebbe non bastare: in uno scenario a due nodi bisogna considerare che un singolo nodo, nel caso peggiore deve avere abbastanza risorse per tutte le VM critiche. E’ anche vero che molti server abbondano di banchi DIMM, come pure i banchi da 32 GB RAM sono diventati economicamente convenienti.
Per infrastrutture iper-convergenti sia il processore che la RAM vanno pianificati con cura!
Security
La sicurezza, negli scenari ROBO, viene di solito trascurata o considerata come ultimo aspetto. Non perché non sia rilevante o importante, ma perché si tende a minimizzarne l’impatto che può avere sulle filiali, focalizzando normalmente l’attenzione sulla sede centrale.
Ma se si condiera l’assenza (in molti casi) di personale IT nelle sedi remote, come pure la ridotta sicurezza fisica che si potrebbe avere, allora la sicurezza è forse uno dei rischi maggiori di questi scenari!
Per alcuni servizi si possono utilizzare delle scelte architetturali specifiche, come ad esempio di Read Only Domain Controller (RODC) per Active Directory. Ma in generale ci si affida alla cifratura dei dati che può essere affrontata in modi ed a livelli diversi:
- Storage level: dischi di tipo Self-encrypting drives (SED) sono possibili, ma normalmente la soluzione è costosa.
- Virtualization level: a partire da vSphere 6.5 vi è una nuova funzione di VM encryption (anche Windows Server 2016 Hyper-V ha qualcosa di simile chiamata Shielded VMs). Come pure esistono soluzioni di terze parti.
- Guest level: Windows Server ha la feature chamata BitLocker per cifrare l’intero volume (come pure ha una funzione per cifrare a livello di singoli file). Le distribuzioni Linux hanno funzioni simili.
In tutti questi casi però, la gestione delle chiavi è un aspetto molto importante e spesso sottovalutato. Come pure si potrebbe sottovalutare l’impatto che ha la cifratura dei dati su aspetti come le prestazioni o la recoverability o la data protection.
Licenze
 In uno scenario ROBO più si riesce a risparmiare e meglio è: ogni costo per singola filiale subisce poi un fattore moltiplicativo per il numero di tutte le filiali! Le licenze possono incidere sul costo complessivo.
In uno scenario ROBO più si riesce a risparmiare e meglio è: ogni costo per singola filiale subisce poi un fattore moltiplicativo per il numero di tutte le filiali! Le licenze possono incidere sul costo complessivo.
VMware vSphere ESXi è licenziato tipicamente per socket, ma esiste un’interessante licenza di tipo ROBO venduta per VM (25 VM per “pacchetto”). La licenza ROBO advanced (adeguata per molti casi ROBO) si aggira sui 180€ per VM che è decisamente conveniente (per poche decine di VM) sia della licenza ESXi Standard ( sui 1000 € per ogni socket) o persino della Essential Plus Kit (sui 4000€ per 3 host e 6 socket). Il vantaggio della licenza ROBO è che indipendente dal numero di host o dal numero di processori. Per contro richiede una licenza vCenter Standard già esistente (da tenere in conto) e le varie VM di tipo virtual appliance (o VSA per soluzioni iper-convergenti) contano comunque una VM.
Le licenze di Windows Server rimangono per socket (più precisamente per coppia di socket), ma a partire da Windows Server 2016 con numero massimo di core. Per poche VM potrebbe persino convenire l’uso di licenze Windows Server Standard.
Per lo storage le licenze dipendono da molti fattori, ma soprattutto dal tipo di storage: alcuni vendono lo storage “a peso” e si paga l’appliance, altri hanno licenze sulla capacità, altri sul numero di dischi, …. Alcune funzioni potrebbero essere a pagamento.
Per quanto riguarda le soluzioni iper-convergenti, la VSAN è licenziata normalmente per socket (ma anche qua esiste un pacchetto ROBO per VM, conveniente per poche VM), mentre le soluzioni basate su VSA sono normalmente licenziate per capacità.
For VMware VSAN la licenza ROBO si aggira sui 500€ per VM (a cui ovviamente bisogna aggiungere il costo dei dischi richiesti), ma comparata con la licenza per socket è vantaggiosa fino ad una decina di VM (si parte da 2500€ per socket for VSAN Standard edition).
Le soluzioni di backup native per la virtualizzazione sono normalmente licenziate a socket.
Vedere anche:
Nel prossimo post vedremo che tipo di infrastrutture è possibile implementare in un’ufficio remoto.

Related Posts

Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
