

This post is also available in: Italian
Reading Time: 5 minutesA3CUBE Inc., a company founded in 2012 as a result of more than 5 years of research and development operations, has introduced its Fortissimo Foundation building block software solution. Coupled with A3CUBE’s previously announced RONNIE Express platform, Fortissimo Foundation provides dramatic improvements in application performance and datacenter efficiency, particularly in unstructured, Big Data environments.
This solution is not only a new approach to a scale out architecture (confirming this kind of storage trend) but also an innovative way to build converged (and also hyperconverged) systems.
I’ve got the opportunity to talk with Antonella Rubicco (Founder and CEO) and Emilio Billi (Founder and Chief Technology Officer) and learn more about this solution.
The idea of this new approach has stated considering how applications requirements are changing! Virtualization is not the only that is driven new requirements, there are also Big Data, unstructured new databases (or applications) HPC, …
There is a need for a new parallel approach to data that will fit with emerging software approaches.
The existing scale-out and (hyper-)converged solutions does not necessary fit in all those cases: for sure they are fine for virtualization, but what happen when we have really I/O intensive applications with really huge amount of data?
Most of the scale-out solutions has some possible bottlenecks: metadata synchronization, maybe a single metadata node, networking scalability limit, … Initially they can grow linearly, but they will reach some limits and cannot grow more or can grow without significant improvements.
Fortissimo Foundation is a clustered, pervasive, global direct-remote I/O access system that linearly scales I/O bandwidth, memory, flash and hard disk storage capacity and server performance to provide an “in-memory” scale-out solution. Fortissimo intelligently aggregates all resources of a data center cluster into a massive global name space, bridging all remote compute and storage resources to look and act as if they were local.
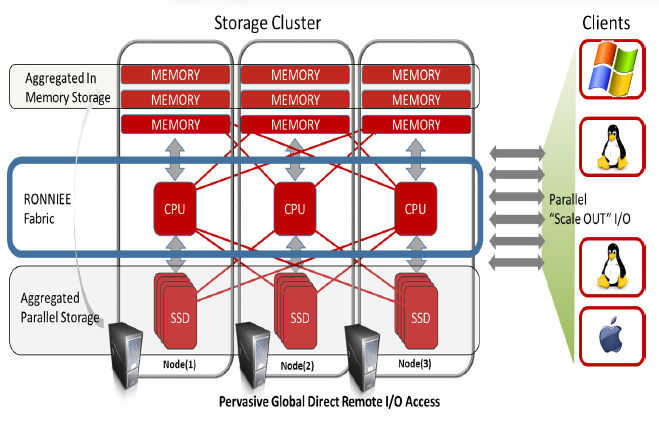
Using the revolutionary RONNIEE Fabric is possible have each node’s CPU accessing both memory and SSD from other nodes at the “same” (local CPU to remote memory latency is less than 800 nano seconds!) speed of local memory and local SSD.
In this way is possible guarantee a linear throughput scalability and build a new type of (hyper-)conververged solution.
In order to build this kind of solution you need one (or more) RONNIEE card (to build the RONNIE Express Storage Fabric), some commodity hardware (you are free to choose what you prefer, remaining in the x64 Platform) and Fortissimo Foundation, that is mainly the Operating System (build on the top of a Linux core) for this solution:
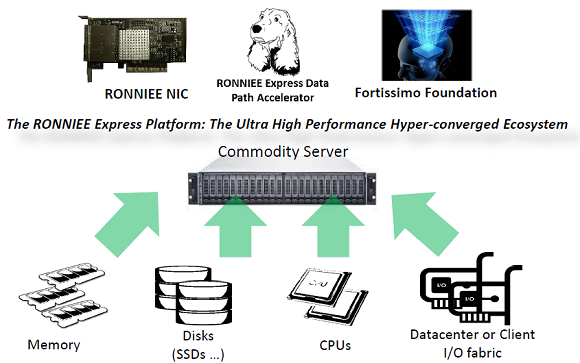
In this way you are able to build a storage pool with server memory that act as a first tier (of course with the right redundancy consideration) and SSDs (or traditional spindles) that act as a second tier.
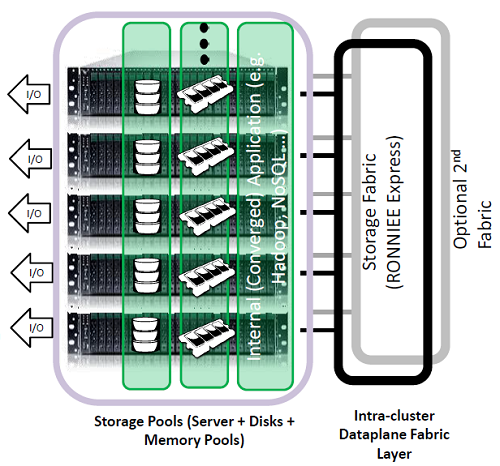
Both the disk pools and the memory pool could be access as a single distribuited and paraller filesystem in order to provide a direct access for new application (for example in order to build a converged Hadoop cluster). This filesystem is an extension of existing Linux filesystems, so could run with ext4, but the suggest one is the parallel version of ZFS.
For existing environments or legacy application, is possible export the filesystem with CIFS, NFS or also iSCSI.
Fortissimo Foundation will not only provide the unified file system, but several other features:
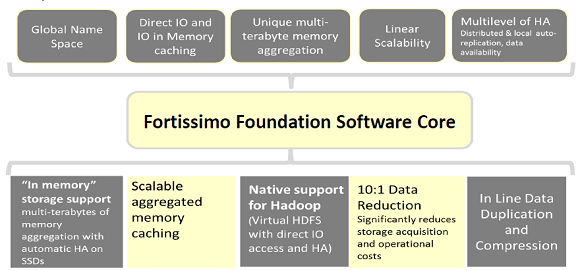
Of course the most innovative part and the piece that enable this kind of approach is the intra-cluster dataplane fabric that is build with special RONNIE Express card used to build a special fast and lot latency network (is not a TCP/IP network and is not seens as a network, but mainly as a fabric with resources directly mapped in memory). This network could be build with several topologies also without any need of switches and with and auto-configuration mode. Also a second fabric could be build in order to provide more redundancy, but note that also in case of the entire fabric failure, all storage traffic could be redirect (of course with less performance) thought the traditional network.
Although this card and this fabric has been developed by A3Cube, there are API to build other solutions based on this fabric (for example, the University of Turin, in Italy, is building a solution to aggregate all the GPU in each node in a single pool).
And what about virtualization? As written this approach could be used also to build hpyer-conververged systems. Of course, considering that the core is Linux, actually the first supported hypervisor are KVM and Xen. But they are working tightly with VMware in order to build a good porting also for this Platform (actually there are some possible issue in current VMware’s PCI passthought that can introduce too much latency for this kind of solution).

Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
