

This post is also available in: Italian
Reading Time: 5 minutesNote: the company has closed all operations on January 2018.
During the last IT Press Tour (the 14th), in the Silicon Valley (December 1-5, 2014) we met several companies in different categories (Cloud, Storage and Big Data).
The third company that we met on the fourth day was Primary Data and potentially their product could be one of the most disrupting in the storage arena.
![]() After the welcome from Shannon McPhee (Primary Data VP of Communications), Lance Smith (Primary Data CEO) has explain the company’s vision of the storage world and how can change in the future. Their mission is transform the datacenter architectures through data virtualization.
After the welcome from Shannon McPhee (Primary Data VP of Communications), Lance Smith (Primary Data CEO) has explain the company’s vision of the storage world and how can change in the future. Their mission is transform the datacenter architectures through data virtualization.
The company is pretty young: founded in August 2013 by David Flynn and Rick White, emerged from stealth at DEMO Fall 2014 on November 19, 2014 (here the related video). Its headquarter is in Los Altos, CA with offices around the world and currently employs about 80 staff worldwide.
The board of directors came from several experiences in the storage and infrastructure world. And there are also some surprises in the executive team, with Steve Wozniak as Chief Scientist.
But, as written, is their product that could become really interesting and disrupting in the storage arena: mainly is a virtualization/abstraction layer for the storage side (or better… for the data layer).
From this schema, probably it sound similar to other storage virtualization (or “hypervisor storage”) solutions, like DataCore or FalconStor. But this is completely different in the approach an properly it can be defined a data virtualization, instead of a storage virtualization.
The benefits are almost similar to other solutions:
- Dynamic data mobility: aligns the right data with the right resource at the right time to boost efficiency, cut costs, and increase agility throughout the enterprise.
- Simplified manageability: delivers operational savings and seamless scalability to reduce administration workloads and after hours fire drills.
- Optimized performance: by placing data where it best fits the policies set by the enterprise to meet application needs.
- Linear scalability: both performance and capacity scale linearly by optimizing data access across a global dataspace (this is true for PrimaryData, but not always true for other storage virtualization products).
But how this solution is different from other similar (at least in the purpose) products? The product itself is a Software Defined Storage solution but is not a new layer with a storage appliance between the hosts and the storage: Primary Data appliances are just a control plane (called data director) that define the rules on how hosts can reach the storage.
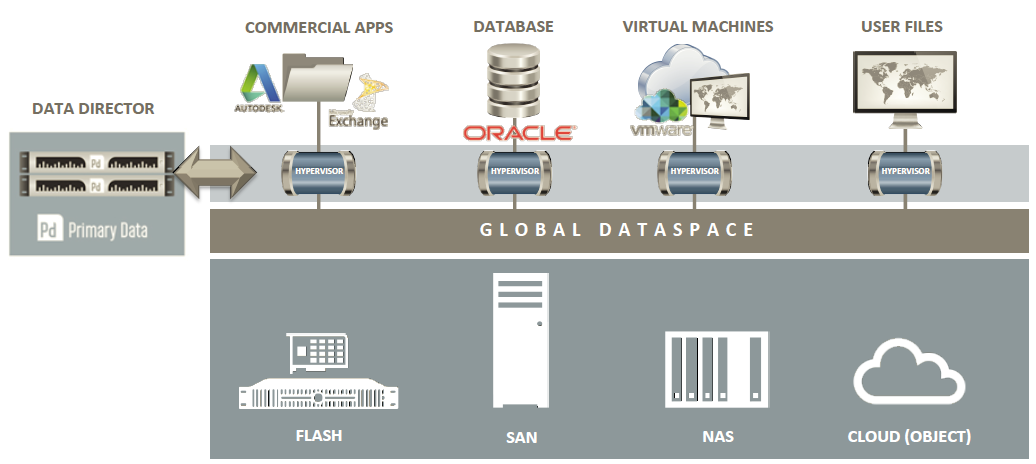
But where is the data plane? In the previous schema there is an “hypervisor” part between the clients and the global dataspace: what is it? It’s just an “agent” or a “filter driver” inside the host that allow the communication with the data directors (usually more than one for availability, and, if necessary, also for scalability) in order to choose the right “paths” to the storage arrays. No agent or driver or API is needed on storage side, that can also be a cloud (or object) storage (S3, Azure, OpenStack Swift).
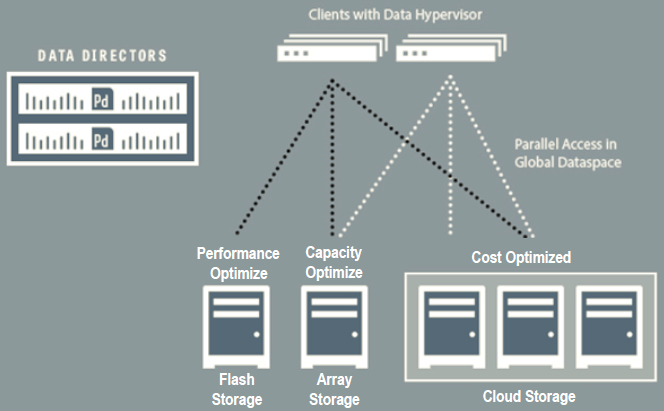
So Primary Data represent a data virtualization solution at file level: each client (usually servers) ask to the data directors how reach the storage (and which storage), the data director will explain at the agent how, and at this point the client can access and work with the storage without talk again with the data director.
The idea itself is not so new: looks like a parallel file system supporting multiple back-ends and pNFS look really similar in the architecture. For sure some idea and models came from there. But here is much general and complete and can be adapted to any environment (of course with the right data hypervisor agent).
Another comparison could be done with a SDN architecture like VMware NSX: some capability at the host level (for part of the data plane) and just a controller (more for redundancy) for the control plane.
At this phase the data directors are just physical appliances, but they are working also on a Virtual Appliance version. But of course more interesting will be see how many operating systems and (bare-metal) hypervisor will include the Primary Data “agent” the main code (or at least how many platform will be supported).
For more information see also those other posts/articles:
- Technology overview
- Primary Data delivers the promises of universal storage
- Primary data is the Nicira of storage!
- Data virtualization surfaces
Disclaimer: I’ve been invited to this event by Condor Consulting Group and they have paid for accommodation and travels, but I’m not compensated for my time and I’m not obliged to blog. Furthermore, the content is not reviewed, approved or published by any other person than me.

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
