

This post is also available in: Inglese
Reading Time: 8 minutesDurante l’ultima edizione dell’IT Press Tour (la 14ma e la prima alla quale ho avuto l’onore di partecipare), svoltasi nella Silicon Valley (nel periodo dal primo a 5 dicembre 2014), abbiamo avuto l’occasione di incontrare molte aziende in differenti aree (Cloud, Storage e Big Data).
La terza azienda che abbiamo incontrato durante il quarto giorno del tour è stata Primary Data, una nuova azienda nel mondo dello storage, ma con una soluzione che potrebbe completamente cambiare questo mondo.
![]() Dopo il benvenuto iniziale di Shannon McPhee (Primary Data VP of Communications), Lance Smith (Primary Data CEO) ha illustrato la vision aziendale e di come pensano (o sperano) di trasformare l’architettura dei datacenter tramite la data virtualization.
Dopo il benvenuto iniziale di Shannon McPhee (Primary Data VP of Communications), Lance Smith (Primary Data CEO) ha illustrato la vision aziendale e di come pensano (o sperano) di trasformare l’architettura dei datacenter tramite la data virtualization.
L’azienda è relativamente giovane: fondata nell’agosto 2013 da David Flynn e Rick White è uscita dallo stealth-mode durante l’evento DEMO Fall 2014 del 19 novembre 2014 (vedere il relativo video dell’annuncio). La sede principale è situata a Los Altos, California con uffici nel mondo e con circa (al momento) 80 dipendenti (globalmente). Stanno adottando una strategia di sviluppo globale, ma una strategia di marketing più locale negli Stati Uniti (come spesso capita per le start-up americane), questa spiega perché il nome forse non si è ancora sentito in Italia.
Le persone del board of director arrivano da diverse esperienze nel mondo degli storage (e non solo), ma spicca (o quanto meno incuriosisce) anche la presenza nell’executive team, di Steve Wozniak (co-fondatore della Apple) in qualità di Chief Scientist. Ipotizzando pure che abbia scelto questo incarico per i soldi, un minimo deve crederci nell’azienda e nella soluzione per investirci il suo tempo.
Ma veniamo al perché questo prodotto (anche se in questa fase è meglio parlare ancora di idea/soluzione) è interessante: in linea di massima è una soluzione di virtualizzazione / astrazione dello storage.
Fin qui nulla di nuovo o comunque nulla che come idea di fondo già non esista: vi sono già prodotti di storage virtualization (alcuni chiamati anche “storage hypervisor “), come da esempio DataCore SANsymphony-V o FalconStor NSS. Ma questo è qualcosa di completamente differente sia nell’approccio che nell’architettura. Più propriamente è una soluzione di data virtualization, più che di storage virtualization.
I vantaggi sono ovviamente simili ad altre soluzioni di storage virtualization:
- Dynamic data mobility: possibilità di spostare i dati in modo trasparente, sia per attività di migrazione, ma anche per ottimizzare le prestazioni o i costi.
- Simplified manageability: unico punto di accesso allo storage che semplica di configurazione e gestione.
- Optimized performance: possibilità di salvare i dati sullo storage più performante.
- Linear scalability: possibilità di scalare secondo un modello scale-out in modo lineare sia come capacità che come prestazioni (questo è sicuramente vero per Primary Data, mentre già potrebbe non essere vero, almeno per la scalabilità lineare sulle prestazioni, per altre soluzioni).
Ma in cosa è così different questa soluzione? Questa una vera e propria soluzione di tipo Software Defined Storage, dove il prodotto in sé non è un semplice strato da frapporre tra gli host (o client) e gli storage. Il prodotto è in realtà più che altro un control plane per definire come accedere ai dati degli storage (nelle schema successivo è indicato come data director).
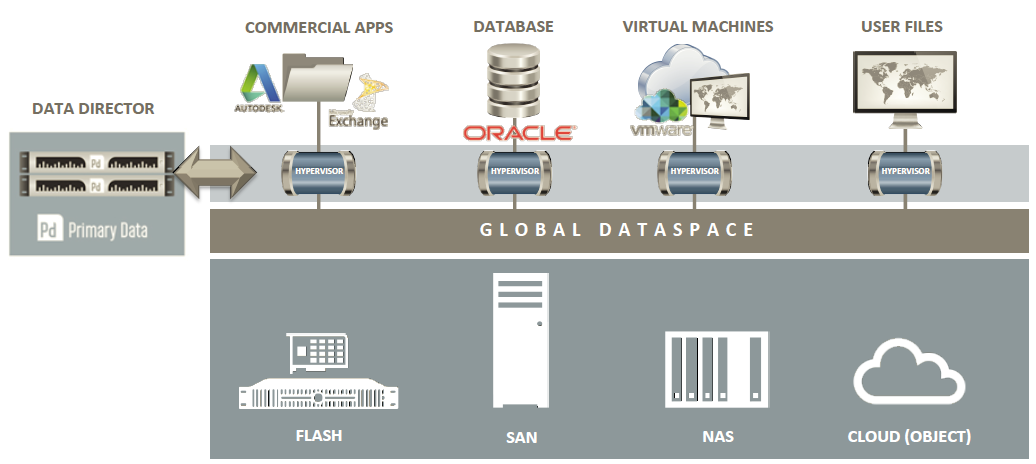
Ma se c’è un control plane, deve esistere anche un data plane che nello schema precedente è rappresentato dalla voce “hypervisor”… ma dove e come è implementato? Anche se nello schema è rappresentato come uno strato tra client e storage, nella realtà è un semplice agent installato nel client (più propriamente è un “filter driver” nel sistema operativo o nell’hypervisor dell’host).
Questo si preoccupa di mettere in comunicazione l’host con il data director in modo da individuare il percorso (o i percorsi) corretti per raggiungere i dati sullo storage. Lato storage non serve alcun driver o agente o API specifica per l’accesso ed è possibile avere anche cloud o object storage (S3, Azure, OpenStack Swift).
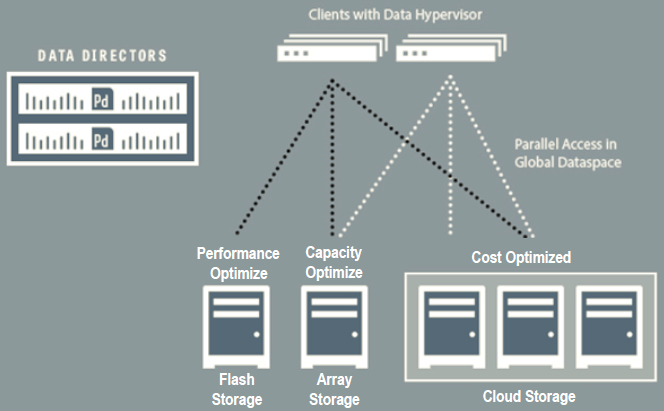
Quindi Primary Data rappresenta un soluzione di data virtualization che lavora fondamentalmente a file level: ogni client (client nel modello, anche se poi saranno ragionevolmente server fisici o server di virtualizzazione) chiede al data directory come raggiungere i dati, questo comunica alll’agente quale sia il percorso o i percorsi più adatti e dal quel momento il client può accedere ai dati senza più passare dal data director. Di fatto il data director mappa l’accesso a file (o volendo anche a blocchi) verso un accesso a blocchi, a file o ad oggetti o cloud.
L’idea in realtà non è proprio nuovissima: guardando al modello proposto per il parallel-NFS (pNFS) si nota qualche similitudine. In effetti il risultato finale è simile, un parallel file system (con un global name space) che supporta più back-end. In questo caso però il tutto è più generalizzabile ed adattabile anche a realtà che non usino il protocollo NFS 4.1.
Un altro possibile paragone è con il mondo Software Defined Networ (SDN) e le relative architetture (come ad esempio VMware NSX): anche qua si possono trovare delle funzionalità di data plane a livello di host e dei controller esterni per il control plane.
Attualmente il data director è un appliance hardware, ma nelle prossime versione dovrebbe essere disponibile una versione Virtual Appliance (VA). Non deve essere visto come un single point of failure, visto che può scalare in modalità scale-out sia per ragioni di disponibilità (e al momento è la principale ragione), ma potenzialmente anche per ragioni di prestazioni.
Sicuramente però il fattore che può determinare o meno il successo di questa soluzione è la disponibilità dell’agente (di quello che viene chiamato “Data Hypervisor”) per la maggior parte dei sistemi operativi (almeno per gli ambienti fisici), ma soprattutto per la maggior parte degli hypervisor (di tipo bare-metal). Secondo Primary Data la parte “agent” è molto piccola e semplice, tanto che potrebbe essere inclusa nel codice di molti sistemi operativi (almeno quelli Linux), o almeno questo è il loro intento… se così fosse questo aspetto (che comunque non è da trascurare) sarebbe smarcato in modo molto furbo.
Ma perché questa soluzione può essere così “distruttiva” nel mondo dello storage? Oggi, in ogni storage che comprate pagate molto la parte software di controllo e le varie feature come le snapshot, il tiering, la replica, … questa componente a volte incide in modo significativo sul costo dello storage (tanto pià che esistono soluzioni di storage solo software, come VMware VSAN o Atlantis USX, che usano server standard o storage già pre-esistenti). Con questa soluzione lo storage deve fare solo da aggregato di dischi (o quanto meno potrebbe fare solo questo), tutta l’intelligenza potrebbe essere spostata nel control plane che decide ad esempio il tiering dei dati (magari in base non solo ad ottimizzazioni per le prestazioni, ma anche ottimizzazioni sul costo)… questo strato potrebbe persino (sulla carta) occuparsi di come ridondare i dati, di come replicarli, … rendendo quindi “stupidi” gli storage veri e propri che possono tornare a fare solo lo storage inteso come aggregato di spazio.
Certo, siamo ancora lontani da questo scenario, ma pensate a cosa potrebbe succedere se un’azienda come VMware (per fare un esempio) dovrebbe acquisire questa tecnologia e renderla mainstream nei suoi prodotti come ha fatto con Nicira (divenuta poi VMware NSX)?
Per maggiori informazioni vedere anche (in inglese):
- Technology overview
- Primary Data delivers the promises of universal storage
- Primary data is the Nicira of storage!
- Data virtualization surfaces
Disclaimer: Sono stato invitato a questo evento da Condor Consulting Group che ha coperto i costi per il viaggio e l’alloggio. Ma non sono stato ricompensato in alcun modo per il mio tempo e non sono in obbligo di scrivere articoli riguardo all’evento stesso e/o gli sponsor. In ogni caso, i contenuti di questi articoli non sono stati concordati, rivisti o approvati dalle aziende menzionate o da altri al di fuori del sottoscritto.

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
