

This post is also available in: Italian
Reading Time: 11 minutesThis is the third part of a set of posts realized for StarWind blog and focused on the design and implementation of a ROBO infrastructure. See also the original post.
Infrastructure at remote office side
Design a ROBO scenario must match finally the reality of the customers’ needs, its constraints but also the type of workload and the possible availability solutions of them.
Logical design of a ROBO scenario
When can found the different type of approaches:
- No server(s) at
- Few servers (that maybe can fail)
- Some servers with “relaxed” availability requirements
- Some servers with reasonable availability
Let’s analyze each of them.
No distributed servers
All is centralized in the main office (or in a public cloud) environment and maybe also desktop are centralized using VDI or some kind of RemoteApp.
From the management point of view this solution it’s easy just because all is centralized and manage and monitoring could be easiest. Also backup, data protection, and availability could be better managed.
But on the other side, WAN connectivity become much critical, not only from the bandwidth point of view (where you need enough bandwidth for each service and each user) but also latency and reliability can impact in the worst way the business continuity requirements and user experience.
In most cases, those constraints will limit this approach, just because it’s difficult to have a good geographical network (especially from the main office that must provide all the services). But using a public cloud (or a hybrid could) be an interesting option.
And in order to reduce the data movements, a VDI approach can help and can provide also “stateless” branch offices (just a router/firewall could be enough with a local DHCP server or relay server), but still you have to consider some kind of data movement across the WAN link that is not only the remote protocol used by the VDI solution (choosing the right one could be critical) but also other streams, like the remote printing operations.
Few servers (that maybe can fail)
This is a very interesting approach that can work only if your application can fail and they don’t need a reliability infrastructure.
As discussed in the previous post, there are applications designed to fail and be high available. In this case, the low technology layers may be not so relevant because they can just fail and the application will handle it.
Some example of this type of application are:
- Active Directory Domain Controllers: one could fail, but clients will work with the others (usually from the main office).
- DFS link with FRS service: in this case, you can one DFS link (the local fileserver), but the client can use the other DFS links and still access the files.
- Caching servers (like Branch Cache) or transparent proxies.
All those services must be carefully planned in order to be sure that services can fail-over on the central site, instead that on another ROBO site.
Of course, this does not mean that you need creepy systems and infrastructure, but with standard solutions with reasonable reliability and redundancy, you can be fine.
Depending on the case you can use a single server (and consolidate the services on it), or better one virtualization host that could be enough in this specific case.
Some servers with “relaxed” availability requirements
If you can have a manual failover or service recovery, there is an interesting option: in each remote site have just two virtualization host with local storage and across replication of the VMs (using native VMware/Hyper-V features or 3rd part solutions).
Each node act as a DR for the other. In this way, you can provide a better availability and recoverability level compared to the previous case and contain costs (like for a shared storage solutions).
Some servers with reasonable availability
If you need local servers and your applications are not designed to fail, you probably fit in this case where you need some kind of infrastructure that provides a reasonable availability level, as discussed in the previous post.
A cluster with two nodes of virtualization hosts could be enough for most ROBO scenarios and for the storage side there can be some approach, but at the logical level, you need a shared storage.
Physical design
NAS Appliance
In most cases, you need a local archiving space that could be provided by a NAS appliance.
Most of them provide already several infrastructure services, like DHCP, DNS, NTP, … but can also add some “apps” to increase those services, for example by adding proxy capabilities.
In the case of few servers that maybe can fail (due to the applications designed for a better availability), those kinds of appliances could be more interesting.
For example, Qnap can also run native VM inside it (but also other low-cost NAS solutions have this feature), using KVM as an hypervisor (of course there are only basic virtualization features).
Of course, it’s limited by the limited resources of the NAS appliance, but in most cases could be enough for one or two small VMs.
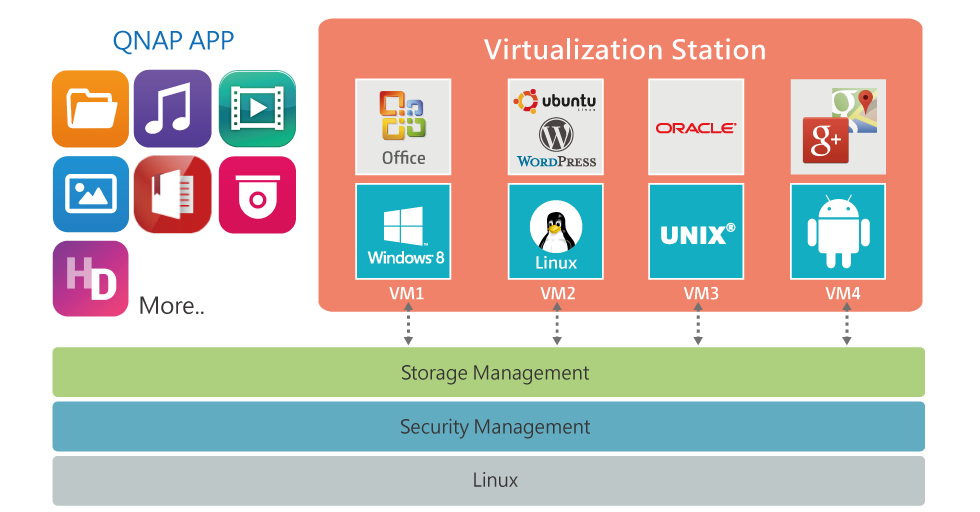
Note that most of those NAS appliances provide also file replication abilities (normally with rsync service) that could be interesting to keep mirrored copy of the remote data.
Physical Server
Unless the previous example, you probably need some (in most cases just two) physical server and you will use them as a virtualization platform. 
One important aspect to consider is form factor. Space could be a constraint. Depending on the environment and the facilities at the remote office maybe you need small rack mountable servers (1 or 2 unit) and check also the depth of them (compare to one of the racks).
But maybe the rack it’s just too small (designed only for network equipment’s) and, in this case, a tower form factor could be good enough (it also provides more space for expandability).
Out of band management, it’s a must to permit a good remote manageability and also remote monitoring, so just include the right ILOE (for HP), iDRAC (for Dell), … licenses and features (not only remote monitoring but also remote console and remote power management). In this was local KVM switches or local monitor, keyboard and mouse are totally unnecessary.
For physical server sizing you have to consider:
- CPU: it’s better a single or dual socket solution? Most software licenses are per socket, so one could be enough (considering also the power of the new generations), but consider also the maximum number of 16 cores for Windows Server 2016 licensing! Minimum core frequency could depend on the workload requirements, but unless you have old applications (not designed for multicore scalability) or really CPU intensive application, usually it’s not a big constraint.
- RAM: in a two-node cluster configuration one node must run all the critical workload. So in most cases, 32 GB could be considered the minimum amount of memory. Note that actually, 16 GB and 32 GB DIMMs are the best deal (if you consider the cost per GB), so also with one CPU configuration, you can have enough RAM in your host.
- Network cards: you probably need at least 4 NICs at 1 Gbps (could be difficult see a remote office with 10 Gbps network switches), but depending on the type of the storage you may need more.
- Storage cards: VMware ESXi could be installed on an SD flash memory (use the redundant configuration) that permit to have diskless hosts. But for other hypervisors, you need at least the RAID1 two disk configuration for the “operating system” so a storage RAID card it’s needed. For local storage or hyperconverged storage solutions, you need a proper card.
- Local disks: maybe needed for local storage or hyperconverged storage. More detail will be provided in next post.
- SAS cards: you may need them for SAS external storage, but also for tapes. Using VMware DirectPath (PCI pass-thought) make possible build (with some limitations) a VM directly connected to an SAS device, useful to reduce the number of required physical servers.
Of course, you need to consider also the power supplies, but two medium power could be enough. You can expect a power consumption around 150W for a 2 sockets configuration or around 120W for a single socket configuration.
New servers are also compliant with fresh air cooling: instead of the traditional idea that enterprise hardware cooling has to be kept at a chilly 20°C/68°F and provided only by a tightly controlled A/C environment, with fresh air hardware-specific configurations is possible work at higher temperature and humidity levels (depending on the server, but also up to 45°C/113°F at a 29°C maximum dew point).
Storage
On the storage part there are some possible options:
- Only local storage with no shared storage at all: host availability is limited, so you have to plan at least a storage replication solution according to your RPO and RTO requirements. In the case some servers with “relaxed” availability requirements this could be acceptable and VM replication is provided both at hypervisor level (VMware with vSphere Replication and Hyper-V with its native, starting from Windows Server 2012).
Note that it’s still possible to migrate VMs live using VMware vMotion (starting from vSphere 5.1) or Hyper-V Live Migration. - Local storage, but with an hyperconverged solution: this case can provide a full cluster set of features and will be discussed later.
- External shared storage: although there are several options (SAN or NAS), for ROBO scenario the most interesting external storage is the shared SAS storage, really easy and relatively “cheap”, could be also reliable (with a dual controllers configuration) and flexible (in most solutions you can mix different types of disks).
The only big limitation of this solution is the scalability limit: but in most cases, it’s scalable up to 4 nodes that are quite enough for a ROBO scenario! - NAS: there are a lot of cheap NAS appliance that can also work as a shared storage for VMware ESXi hosts (or using iSCSI also for Hyper-V hosts), but honestly those solutions are really limited in performance and in reliability (just a single system, with only redundancy at power supply and disks levels). Not suitable if you need an infrastructure with a good availability level.
For the type of disks now SSD are becoming more interesting rather than 15k spinning disks, but still more costly compared to 10k and, especially, Near-Line disks.
Converged solutions
Converged solutions can integrate storage, network and compute resources in a single chassis. Modular blades are a good example of this kind of solutions, but not suitable for ROBO cases.
More interesting is the Dell PowerEdge VRTX product that can target really well the ROBO cases providing up to 4 server nodes and several shared disks (up to 25 using 2,5” or up to 12 using 3.5”). It can also include an internal switch. All in a tower form factor (or rackable in a 5U size).
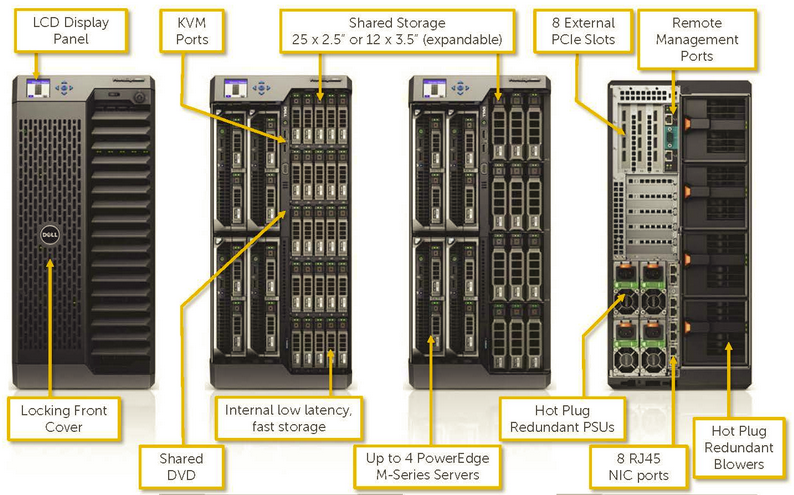
Smart and with some interesting software functions, like the central management/monitoring and the geographical view of all the VRTX.
But it can cost more than next solution, and the internal switch does not provide any redundancy, except using a second external switch.
There is also the Dell FX2 as an interesting converged solution but it’s not targeted for SMB.
Hyperconverged solutions
HCI (Hyper-Converged Infrastructure) is an interesting trend in storage and virtualization world.
By using standard servers both with local storage capacity (and, of course, with computing capacity) and specific software layer to convert local disks in shared storage and have the same (main) features of external shared storage with the big advance to save space and devices.
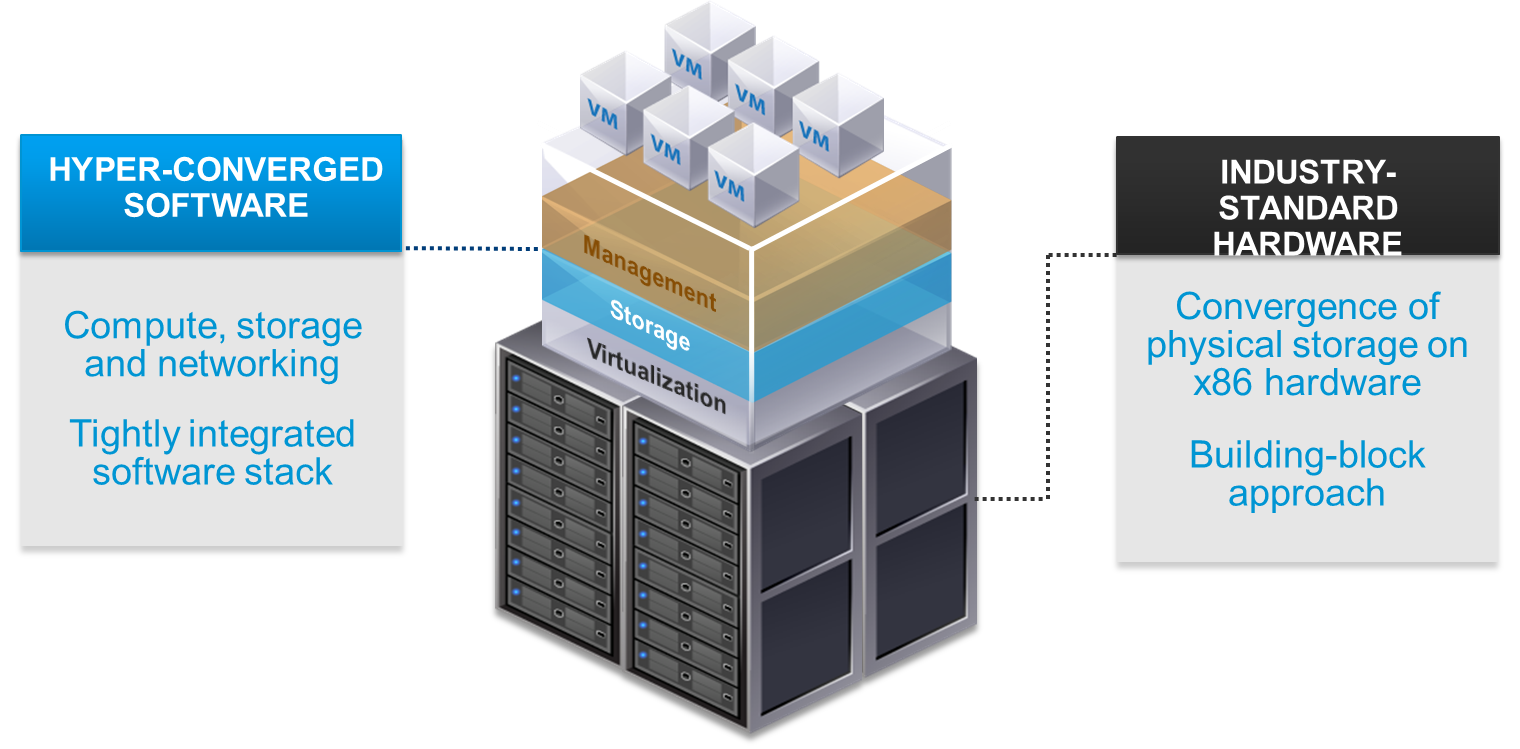
Those solutions usually scale from 2 or 3 nodes up to several nodes (depending on the technology and the product):
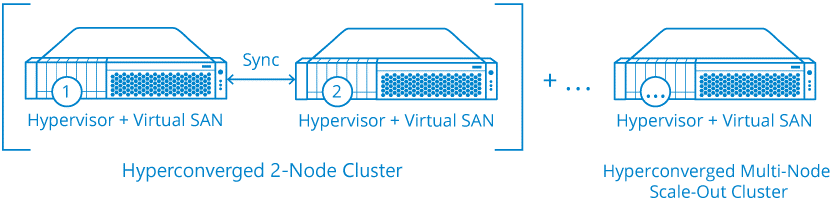
But of ROBO scenario the most interesting configuration is the two nodes configuration, so not all hyperconverged solutions could be suitable for this case (for example Nutanix or Simplivity need at least 3 nodes).
In the next post, we will cover more deeply a configuration with 2-nodes hyperconverged.
Related materials:
- Design a ROBO (Part 1): Introduction and high-level design
- Design a ROBO infrastructure (Part 2): Design areas and technologies

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
