

This post is also available in: Italian
Reading Time: 3 minutesWith the new VMware vSphere 6.0 there are several improvement in the availability related features. Although the vSphere HA apparently has not changed so much (of course now support a bigger cluster with 64 nodes), there several aspects that have been improved or changed:
- New MSCS capabilities
- New vSphere VM Component Protection (VMCP)
- Network partition manament
- New VMware FT-SMP
For more information see also:
MSCS capabilities
Starting with vSphere 5.5 there were several improvement in MSCS capability described in KB 2052238 (MSCS support enhancements in vSphere 5.5).
The three main type of guest cluster supported remain:
- Clustering MSCS Virtual Machines on a Single Host (CIB)
- Clustering MSCS Virtual Machines Across Physical Hosts (CAB)
- Clustering Physical Machines with MSCS Virtual Machines (N+1)
But now there is also support for Windows 2012 R2 and SQL 2012, both in Failover Clustering and AlwaysOn Availability Groups configuration.
Note that using clustering across physical hosts (CAB) with Physical Compatibility Mode RDM’s, the supported OSes are: Windows Server 2008, 2008 R2, 2012 and 2012 R2.
Seems also that vCenter Server could be run on a FailOver Cluster (of course only the Windows version), but this must be confirmed in the final documentation.
VMCP
The new vSphere VM Component Protection (VMCP) is a way to protect VMs against storage connectivity failures and misconfigurations and was a big limit of previous version of VMware HA that was only able to detect network failure for hosts (and only on some networks).
With vSphere there are mainly two different cases of storage failure:
- All Paths Down (APD): represents a transient or unknown accessibility loss or any other unidentified delay in I/O processing. This type of accessibility issue is recoverable.
- Permanent Device Loss (PDL): is an unrecoverable loss of accessibility that occurs when a storage device reports the datastore is no longer accessible by the host. This condition cannot be reverted without powering off virtual machines.
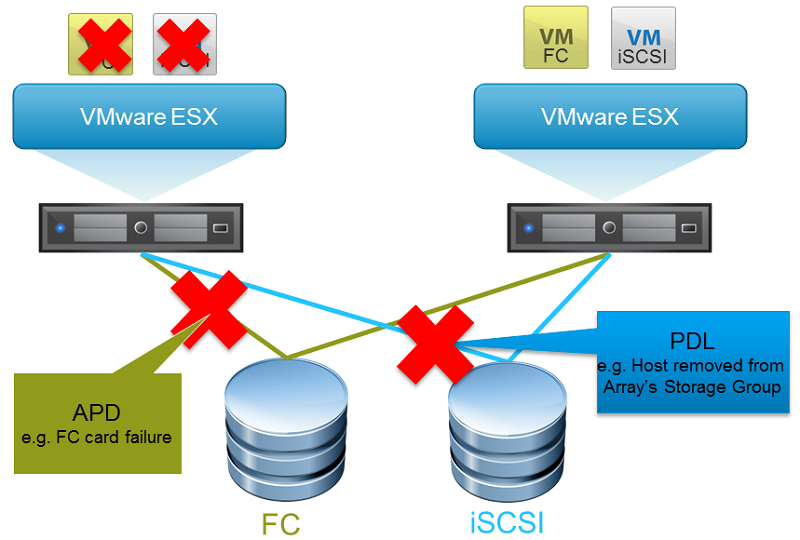
Starting with vSphere 5.5 there where some big improvement on how handle APD and PDL, but still a host storage failure was a big issue. The simple solution was design the storage to don’t fail.
VMware FT can now protect a VM also from storage failure, but finally it’s possible handle this issue also with vSphere HA for all VMs and all datastores with full customization of responses:
- APD: Terminate VM after user-configured timeout only if there is enough capacity; restart on a healthy host. Reset a VM if APD clears after APD timeout
- PDL: Terminate VM immediately; restart on a healthy host
There are detailed reporting of conditions and actions taken included impacted VMs, host(s) and datastore(s).
For an example on how this feature works see this video:
Network partition
When a management network failure occurs for a vSphere HA cluster, a subset of the cluster’s hosts might be unable to communicate over the management network with the other hosts. Multiple partitions can occur in a cluster. A partitioned cluster leads to degraded virtual machine protection and cluster management functionality.
Depending on where is vCenter Server and which hosts can be reach there are some cases explained in the Availability Guide. Also vSphere HA uses datastore heartbeating to distinguish between partitioned, isolated, and failed hosts.
VMware FT
For more information see the related post.

Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
