
This is the last part of a set of posts realized for StarWind blog and focused on the design and implementation of a ROBO infrastructure. See also the original post.
Design a ROBO infrastructure. Part 5: Data protection solutions
Business continuity aspects
In previous posts we have already discuss about several business continuity aspects in ROBO scenarios.
For example, a reasonable availability level could be between 99% and 99,99%, but there are some workloads that may require higher level (or other that are not critical at all). But availability could be achieved by a good infrastructure design and for ROBO a two nodes cluster could be a reasonable approach.
More important is the recoverability: the ability to restore your services and data to the point at which a failure occurred. It can be strictly related to the availability aspects, but usually you are going to cover events and cases where high availability solutions cannot help.
Recoverability does not care about the different layers that you have, it requires that you recover the services (also on a different stack).
The ability to recover quickly from a system failure or disaster depends not only on having current backups of your data, but also on having a good plan for recovering that data and the related services. In this case it’s related to disaster recovery aspects (but, of course, still with all the data and system protection solutions that you have to implement).
Backup and data protection are a pillar for recoverability and disaster recovery plans, so let’s discuss how implement them in a ROBO scenario.
Data protection approaches
Like other design choices we have to match the following technology aspects to satisfy design requirements:
- Availability
- Manageability
- Performance and scaling
- Recoverability
- Security
- Risk and budget management
Of course the most important aspect to be considered is the recoverability aspects combined with the availability of the data. For backup usually the 3-2-1 rule is used to satisfy those requirements and represent a great start for the majority of people and businesses (even the United States Government recommends it in a 2012 paper for US-CERT).
The 3-2-1 backup plan implies that you must:
- Have at least 3 copies of your data (the first one would be your actual data, wherever they reside).
- Keep these backups on 2 different medias and technologies, usually one backup remain locally to improve both backup speed but also reduce the recovery time.
- Store at least 1 backup offsite, that could mean a removable storage (like USB disk or tape) or a remote replica or a cloud backup.
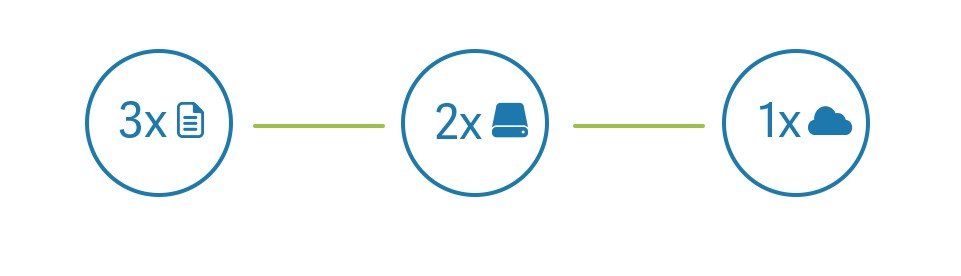
Backup to disks and tapes can easy satisfy this rule, but also backup to local disks and an offsite replica or cloud backup can also work. All depends by your bandwidth constraints and also by regulamentations or compliances requirements.
Management and monitoring are also important aspects due to the size of the infrastructure (not inside a single remote site, but globally) and the geographic distribution of the entire environment.
As written, one of big risk in ROBO scenario is the lack of local IT staff: usually all the IT people are located in the main office and moving them to a remote office could be cost.
For this reason, remote management is a must and, at least, systems and services monitoring should be centralized. Management also could be centralized, but it’s not mandatory, because it could be enough a remote management capability.
For the backup and data protection solutions usually management could:
- Centralized: one single console for all, both for monitoring and management, usually located in the main office, with distributed resources for handle the backup and store the data. Note that not all backup solutions can be built in a distributed way with a central management.
- Distributed: each remote office is an island with its own backup infrastructure managed independently. Still it’s possible, with some backup product, to have a global centralized dashboard and central monitoring of the environment.
The choice depends mostly by the network constraints (mostly the bandwidth and the latency, but also the reliability could be really important): in some case a centralized management could be possible or be not manageable at all (for example, with Veeam Backup and Replication the console could become really slow if you have a network latency greater than 400ms and backup jobs could be interrupted if you have network loss).
Performance and scaling aspects are usually not relevant in a backup design for ROBO scenario, at least not for the remote offices. If you have a central management than the design of the solution in the main office should also consider scaling and performance aspects.
Security aspects could be critical and for off-site data encryption is a must, but can also be useful for all the control data.
Logical design
Depending by the backup solution, you can have several components, roles and servers. But usually in most solutions you have at least one backup server and some other components.
Names could be really different depending by the backup product, so to make just an example let’s consider Veeam Backup and Replication v9 or later.
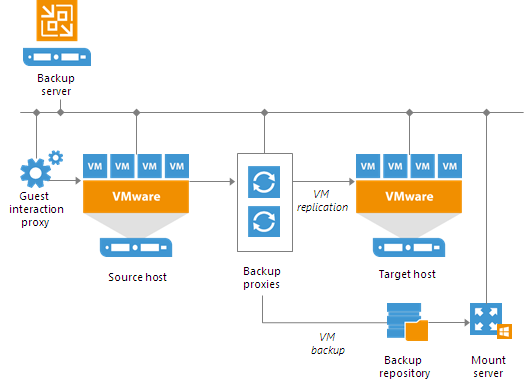 In this case the (most relevant) components names are:
In this case the (most relevant) components names are:
- Veeam Backup Server: is the management server with the backup engine and all the jobs (in a centralized implementation this is just one in the main office, in a distributed there will be one for each remote office).
- Veeam Enterprise Manager (optional): this can be used to have a centralized dashboard for multiple Veeam Backup Server and can be really useful in a distributed implementation.
- Veeam Repository: a storage location where you can keep backup files, VM copies and metadata for replicated VMs. Depending by your architecture and design choices you may need one repository for each remote office.
- Veeam (Backup) Proxy: it’s a component that sits between the backup server and other components of the backup infrastructure. While the backup server administers tasks, the proxy processes jobs and delivers backup traffic. For each remote office you need at least one proxy component (and one usually it’s enough).
- Tape Server: a server or a component that manage the physical tape loader.
- Guest Interaction Server: it’s a component that sits between the backup server and processed VM. This component is needed if the backup or replication jobs perform application-aware processing, guest file system indexing, transaction logs processing. Still you need at least one for each remote office, and usually this role could be implemented by the proxy server.
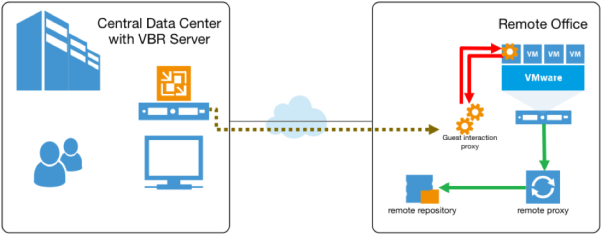
- Mount Server: required if you perform restore VM guest OS files and application items to the original location. The mount server lets you route VM traffic by an optimal way, reduce load on the network and speed up the restore process. Again, it could be the proxy server.
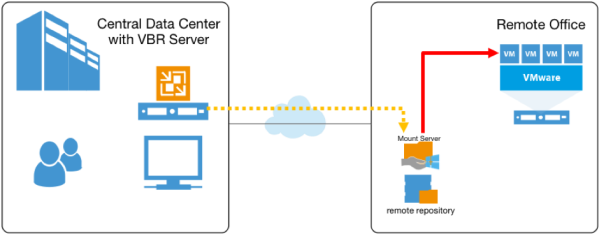
There are also other components, but those are the most relevant for a ROBO scenario.
For other backup products the name could be different but the role functions and the logic will be remain similar.
Have local target/repository of the first backup level and local resources to handle the backup (in the previous case the backup proxy and guest interaction proxy) it’s usually mandatory in a ROBO scenario to reduce the backup (and recover) timings. If bandwidth it’s a constrain, then network throttling could be useful to limit the management/control/data traffic and, if remote replicas are used, a WAN accelerators could also improve network usage.
Physical design
Depending by the required components you may need, for each remote office, at least one server to implement the data protection solution. More servers could be too expensive so could be reasonable collapse more components in a single server.
The remote “backup” server could be:
- Physical server: it means another server to manage, but also more costs (one for each remote office), more required space, more complexity, … but the main advantage is that it’s totally (or at least it’s physically) independent by the infrastructure that you want to protect
- Virtual server: you put in the same infrastructure that you want to protect, that mean no additional physical server, but potentially additional license costs (for example vSphere for ROBO count each VMs). Also in this case it’s very important define where is the target /repository of the backup data, because it must be on a different storage than the main used for the primary storage. An external NAS could be a possibility, but also a set other local disks used only for backup purpose could be another possible solution.
- Appliance approach: there are some interesting backup solution appliance based (physical or virtual). Some could be “too big” for ROBO (for example Rubrik or Cohesity, although both are trying also to cover the ROBO scenario with some specific solutions), other could appear “too small”, but maybe are the most interesting.
First let’s consider the small NAS solutions because could be really interesting for small ROBO environments and represent a cheap solution.
Qnap, Synology, but also WD and other “entry level” solutions, have embedded backup solution to protect some workloads via agent (or third part backup products) using the NAS a target with embedded replica capability to another NAS (usually via rsync service) and also with cloud storage copies:
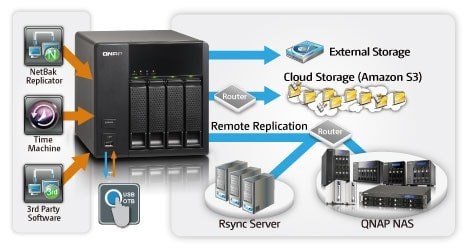 Enough for some use cases, for enterprises and medium ROBO could become too complex or too limited.
Enough for some use cases, for enterprises and medium ROBO could become too complex or too limited.
But third part integration is the key and several solutions are now starting to consider also those NAS. For example, Nakivo Backup can run natively on Qnap (using a standard app from the store!) or Synology or WD NAS. Another example is Xopero that has also a QNAP Appliance implementation. In those cases, all the backup components are inside the NAS appliance!
In a more traditional approach, backup a NAS could be used but only as a target for the backup and all the components run on a local server, usually a virtual machined to limit the number of the physical server.
In this case could be interesting how implement the off-site copy of your data: as written it could be cloud backup (but maybe it’s not possible due to bandwidth limitation or compliance restriction) or could be a remote replica or copy job (but maybe it’s not possible due to bandwidth limitation).
Or, using an old style approach it could a tape. A single Ultrium LTO cartridge could be enough to store all the data from one remote site (with LTO-5 you can have 1,5TB of space, with LTO-6 2,5TB!) with interesting cost per TB and the ability to store you tapes in a proper and secure way (there are also several vault services). So a single tape loader (for each remote site) could be enough if you are planning this type of approach.
But how it’s possible handle a tape device from a virtual machine to implement this kind of approach?
One solutions could be have an external iSCSI tape, but could be quite expensive and usually this option it’s available on autoloader and not on single tape loader. So normally you will have a SAS tape inside of your virtualization host and you need to connect it to the “backup” VM.
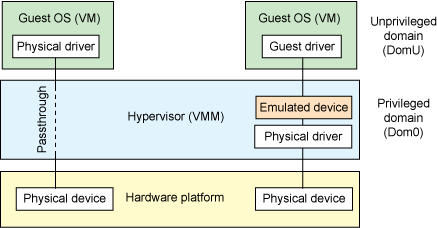
VMware vSphere has two different type of solution:
- SCSI device: in this case you just give the SCSI ID (also present also with SAS devices) to the VM and ESXi will “emulate” the device access. The solution could be easy to implement but could have some performance bottleneck due the emulation process.
- VMDirecthPath I/O: in this case you pass the entire device directly to the VM, that means, for a tape device, that you need a dedicated SAS card that will be handled in a pass-through way directly from the VM. This will give better performance (close to native physical solution), less compatibility problems and issues, but also some limitation (the VM will no more support snapshots and other functions).

For Microsoft Hyper-V there is a new functions introduced with Windows Server 2016, called Discrete Device Assignment. It’s quite similar to VMware VMDirecthPath and implement “device pass-through” for virtual machines running on Hyper-V.
Note that tape could be not the only option to have local removable storage: another option could be use removable disks. In this case USB access could be a must (to use external USB disks or disk loaders) and could be implemented both in Hyper-V or ESXi with the previous “device pass-through” approach. But on ESXi it’s also possible native USB virtualization features that could be more flexible (and can support USB3 device with reasonable performance).

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
