

This post is also available in: Italian
Reading Time: 17 minutesThis is an article realized for StarWind blog and focused on the design and implementation of a stretched cluster.
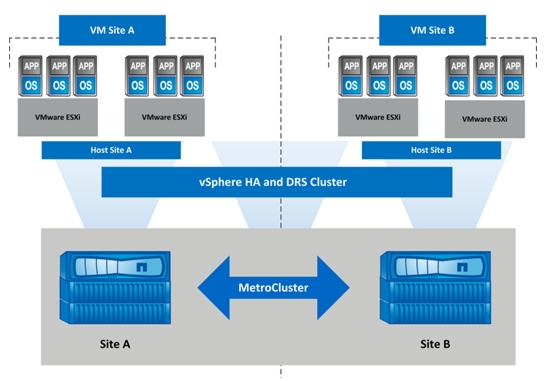
A stretched cluster, sometimes called metro-cluster, is a deployment model in which two or more host servers are part of the same logical cluster but are located in separate geographical locations, usually two sites. In order to be in the same cluster, the shared storage must be reachable in both sites.
Stretched cluster, usually, are used and provided high availability (HA) and load balancing features and capabilities and build active-active sites.
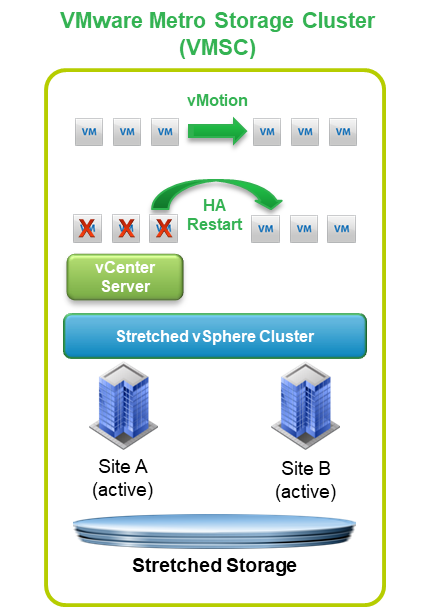
The vSphere Metro Storage Cluster (vMSC) is just a configuration option for a vSphere cluster, where half of the virtualization hosts are in one site and the second half is in a second site. Both site work in an active-active way and common vSphere features, like vMotion or vSphere HA, can be used.
In the case of a planned migration, such as in the need for disaster avoidance or data center consolidation, using stretched storage enables zero-downtime application mobility.
In the case of a site disaster, vSphere HA will provide VMs recovery on the other site.
Requirements and limitations
There are some technical constraints related to the of an online migration of VMs, the following specific requirements must be met prior to consideration of a stretched cluster implementation:
- To support higher latency in vMotion, vSphere Enterprise Plus is required (although this requirement is no longer explicated in vSphere 6.x).
- ESXi vSphere vMotion network must have a link minimum bandwidth of 250Mbps.
- Maximum supported network latency between sites should be around 10ms round-trip time (RTT). Note that vSphere vMotion, and vSphere Storage vMotion, supports a maximum of 150ms latency as of vSphere 6.0, but this is not intended for stretched clustering usage.
- VMs networks should be on stretched L2 network (or that some network virtualization techniques are used). Note that ESXi Management network and vMotion network could be also L3.
For the storage part we need:
- Storage must be certified for vMSC.
- Supported storage protocols are Fibre Channel, iSCSI, NFS, and FCoE. Also, vSAN is supported.
- The maximum supported latency for synchronous storage replication links is 10ms RTT or lower.
The storage requirements can, of course, be slightly more complex, depending on the storage vendor, the storage architecture and the specific storage product, but usually there are both specific VMware KB articles and storage vendor related papers. A vSphere Metro Storage Cluster requires what is in effect a single storage subsystem that spans both sites and permit ESXi to access datastores from either array transparently and with no impact to ongoing storage operations, with potentially active-active read/write simultaneously from both sites.
Uniform vs. non-uniform
There are two main vMSC architectures, based on a fundamental difference in how hosts access storage:
- Uniform host access configuration
- Nonuniform host access configuration
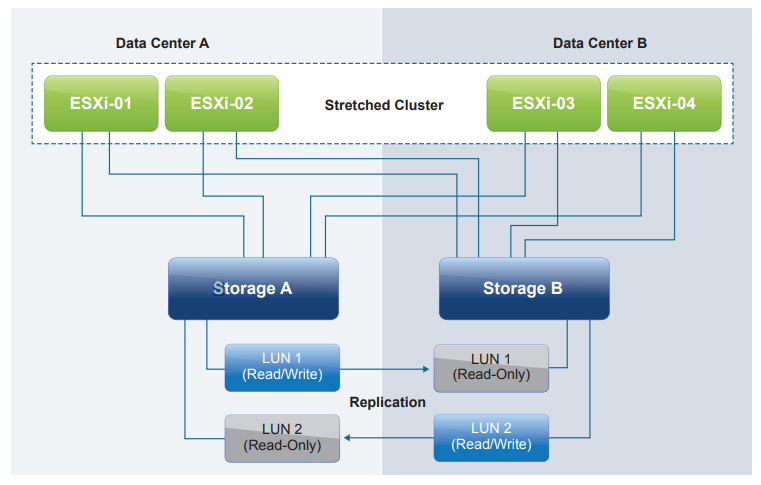
In a uniform architecture, ESXi hosts from both sites are all connected to a storage node in the storage cluster across all sites. Paths presented to ESXi hosts are stretched across a distance.
This tends to be a more common design, which provides full storage access, can handle local storage failure without interruption and helps provide a better level of uptime for virtual machines.
For this type of architecture, we need a way to provide the notion of “site affinity” for a VM to localize all the storage I/O locally in each sited (and define a “site bias”) in order to minimize un-necessary cross-site traffic.
In a non-uniform architecture ESXi hosts at each site are connected only to the storage node(s) at the same site. Paths presented to ESXi hosts from storage nodes are limited to the local site. Each cluster node has read/write access to the storage in one site, but not to the other.
A key point with this configuration is that each datastore has implicit “site affinity,” due to the “LUN locality” in each site. Also, if anything happens to the link between the sites, the storage system on the preferred site for a given datastore will be the only one remaining with read/write access to it. This prevents any data corruption in case of a failure scenario.
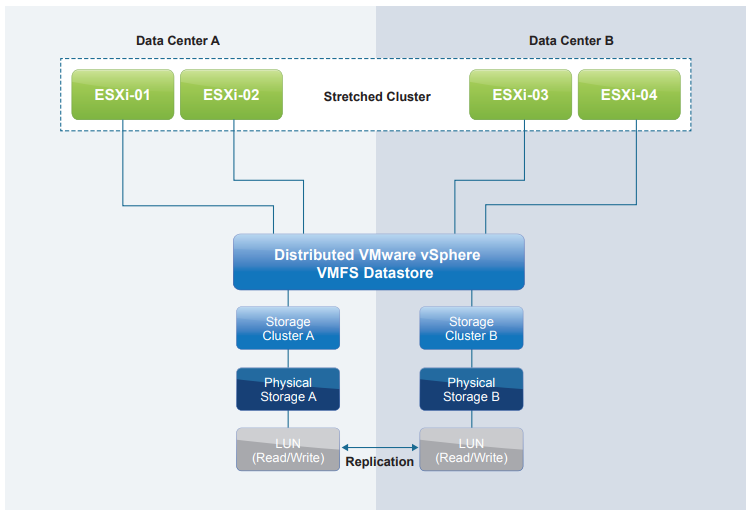
vSphere Metro Storage Cluster supports uniform or non-uniform storage presentation and fabric designs. Within the vMSC entity, one presentation model should be implemented consistently for all vSphere hosts in the stretched cluster. Mixing storage presentation models within a stretched cluster is not recommended. It may work but it has not been formally or thoroughly tested.
Note that vSAN stretched cluster configuration it’s only a uniform more, but with some specific concepts and improvements for data locality and data affinity.
Synchronous vs. Asynchronous
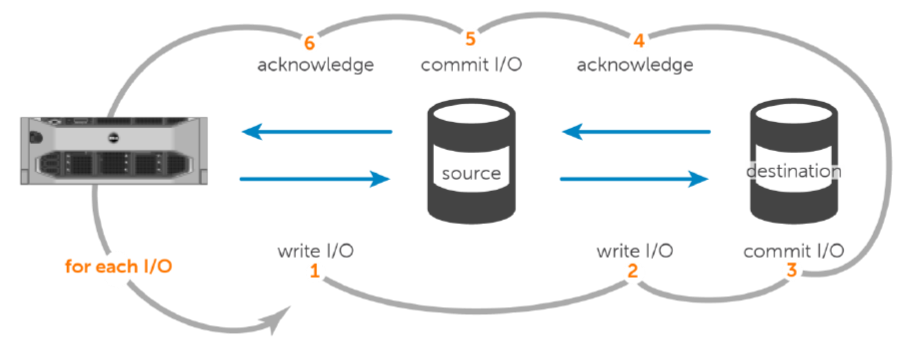
A stretched cluster usually used synchronous replication to guarantees data consistency (zero RPO) between both sites. The write I/O pattern sequence with synchronous replication:
- The application or server sends a write request to the source.
- The write I/O is mirrored to the destination.
- The mirrored write I/O is committed to the destination.
- The write commit at the destination is acknowledged back to the source.
- The write I/O is committed to the source.
- Finally, the write acknowledgment is sent to the application or server.
The process is repeated for each write I/O requested by the application or server.
Note that formally, if the write I/O cannot be committed at the source or destination, the write will not be committed at either location to ensure consistency. This means that, in the case of a complete links failure across sites, in a strictly synchronous replication both storage are blocked!
But there are also some specific products that can have synchronous replication and just hold the replication in case of storage communication interruption. This provides better storage availability but can imply potentially data misalignments if both sites continue in write operations.
Asynchronous replication tries to accomplish a similar data protection goal, but with a not null RPO. Usually, it defines a frequency to define how often data are replicated.
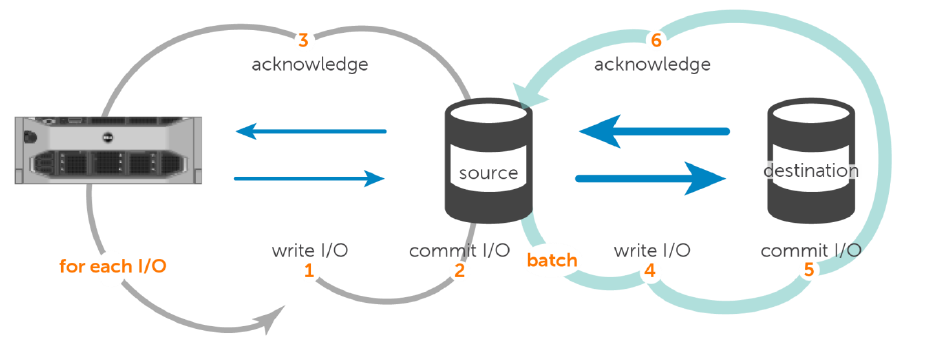
The write I/O pattern sequence with respect to asynchronous replication.
- The application or server sends a write request to the source volume.
- The write I/O is committed to the source volume.
- Finally, the write acknowledgment is sent to the application or server.
The process is repeated for each write I/O requested by the application or server.
- Periodically, a batch of write I/Os that have already been committed to the source volume are transferred to the destination volume.
- The write I/Os are committed to the destination volume.
- A batch acknowledgment is sent to the source.
There can be some variations like Semi-synchronous or Asynchronous not based on schedules, but simply based on snapshot or network best effort in order to reach a close to zero RPO.
The type of replication depends by the storage product and the recommended replication for a stretched cluster, but also by the type of the architecture: in a non-uniform asynchronous can be usable (if the not null RPO is accepted), in a full uniform and active-active cluster, the synchronous should be used.
Of course, the distance can impact on the type of replication (asynchronous support longer distance and remove the storage latency requirement) as also the type of availability.
Stretched storage “only”
A single stretched cluster is a deployment option and requires, of course, a stretched storage. But potentially is possible have only a stretched storage and two different clusters, one in each site, and use the cross-vCenter vMotion to move VMs live across sites if needed.
Site Recovery Manager support this kind of deployment and can use the stretched storage to reduce recovery times: in the case of a disaster, recovery is much faster due to the nature of the stretched storage architecture that enables synchronous data writes and reads on both sites.

When using stretched storage, Site Recovery Manager can orchestrate cross-vCenter vMotion operations at scale, using recovery plans. This is what enables application mobility, without incurring in any downtime.
Note that the SRM model for active-active data centers is fundamentally different from the model used in the VMware vSphere Metro Storage Cluster (VMSC) program. The SRM model uses two vCenter Server instances, one on each site, instead of stretching the vSphere cluster across sites.
Design and configuration aspects
Split-brain avoidance
Split brain is where two arrays might serve I/O to the same volume, without keeping the data in sync between the two sites. Any active/active synchronous replication solution designed to provide continuous availability across two different sites requires a component referred to as a witness or voter to mediate failovers while preventing split brain.
Depending on the storage solution, there are different approaches to this specific problem.
Resiliency and availability
Of course, the overall infrastructure must provide a better resiliency and availability compared to a single site. By default, stretched cluster provide at least a +1 redundancy (for the entire site), but more can be provided with a proper design.
This must start from the storage layer where you must tolerate a total failure of a storage in one site without service interruption (in uniform access) or with a minimal service interruption (in non-uniform access). But site resiliency it’s just a part: what about local resiliency for the storage? That means redundant arrays and local data redundancy for external storage. For hyper-converged this means just local data redundancy with at recommended 3 nodes per sites (or 5 if erasure coding is used). Keep in mind also maintenance windows and activities (for this reason the number of nodes has been increased by one).
Note that vSAN 6.6 provides new features for a secondary level of failure to tolerate, specific for stretched cluster configurations.
VMware vSphere HA
VMware recommends enabling vSphere HA admission control in all cluster, especially in a stretched cluster. Workload availability is the primary driver for most stretched cluster environments, so can be crucial providing sufficient capacity for a full site failure. To ensure that all workloads can be restarted by vSphere HA on just one site, configuring the admission control policy to 50 percent for both memory and CPU is recommended. VMware recommends using a percentage-based policy because it offers the most flexibility and reduces operational overhead.
With vSphere 6.0, some enhancements have been introduced to enable an automated failover of VMs residing on a datastore that has either an all paths down (APD) or a permanent device loss (PDL) condition. Those can be useful in non-uniform models during a failure scenario to ensure that the ESXi host takes appropriate action when access to a LUN is revoked. To enable vSphere HA to respond to both an APD and a PDL condition, vSphere HA must be configured in a specific way. VMware recommends enabling VM Component Protection (VMCP).

The typical configuration for PDL events is Power off and restart VMs. For APD events, VMware recommends selecting Power off and restart VMs (conservative). But of course, refer to specific storage vendor requirements.
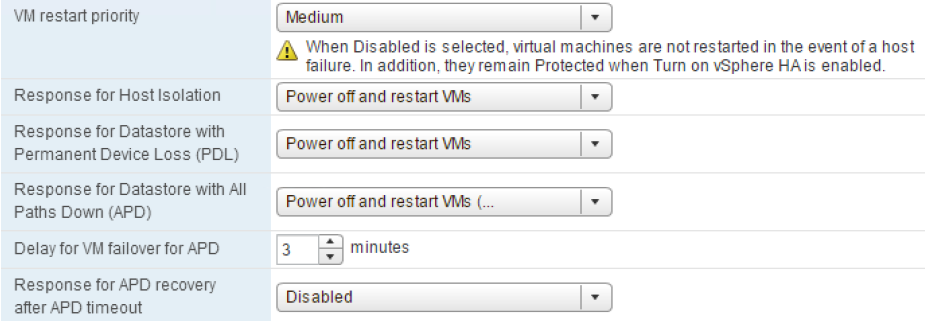
Before vSphere 6.0 those cases were managed by specific ESXi advanced settings like Disk.terminateVMOnPDLDefault, VMkernel.Boot.terminateVMOnPDL and Disk.AutoremoveOnPDL (introduced in vSphere 5.5).
vSphere HA uses heartbeat mechanisms to validate the state of a host. There are two such mechanisms: network heartbeating and datastore heartbeating. Network heartbeating is the primary mechanism for vSphere HA to validate the availability of the hosts. Datastore heartbeating is the secondary mechanism used by vSphere HA; it determines the exact state of the host after network heartbeating has failed.
For network heartbeat, if a host is not receiving any heartbeats, it uses a fail-safe mechanism to detect if it is merely isolated from its master node or completely isolated from the network. It does this by pinging the default gateway. In addition to this mechanism, one or more isolation addresses can be specified manually to enhance the reliability of isolation validation. VMware recommends specifying a minimum of two additional isolation addresses, with each address site local. This enables vSphere HA validation for complete network isolation, even in case of a connection failure between sites.
For storage heartbeat, the minimum number of heartbeat datastores is two and the maximum is five. For vSphere HA datastore heartbeating to function correctly in any type of failure scenario, VMware recommends increasing the number of heartbeat datastores from two to four in a stretched cluster environment. This provides full redundancy for both data center locations. Defining four specific datastores as preferred heartbeat datastores is also recommended, selecting two from one site and two from the other. This enables vSphere HA to heartbeat to a datastore even in the case of a connection failure between sites. Subsequently, it enables vSphere HA to determine the state of a host in any scenario. VMware recommends selecting two datastores in each location to ensure that datastores are available at each site in the case of a site partition. Adding an advanced setting called das.heartbeatDsPerHost can increase the number of heartbeat datastores.
Data locality
Cross-site bandwidth can be really crucial and critical in a stretched cluster configuration. For this reason, you must “force” access to local data for all VMs in a uniform model (for non-uniform data locality is implicit). Using vSphere DRS and proper path selection is a way to achieve this goal.
For vSAN, in a traditional cluster, a virtual machine’s read operations are distributed across all replica copies of the data in the cluster. In the case of a policy setting of NumberOfFailuresToTolerate=1, which results in two copies of the data, 50% of the reads will come from replica1 and 50% will come from replica2. In a vSAN Stretched Cluster, to ensure that 100% of reads occur in the site the VM resides on, the read locality mechanism was introduced. Read locality overrides the NumberOfFailuresToTolerate=1 policy’s behavior to distribute reads across the two data sites.
Other hyper-converged solutions have a specific solution to maximize data locality.
VMware vSphere DRS and storage DRS
To provide VM locality you can build specific VMs to hosts affinity rules. VMware recommends implementing the “should rule” because these are violated by vSphere HA in the case of a full site failure. Note that vSphere DRS communicates these rules to vSphere HA, and these are stored in a “compatibility list” governing allowed start-up. If a single host fails, VM-to-host “should rules” are ignored by default.
For vSAN, VMware recommends that DRS is placed in partially automated mode if there is an outage. Customers will continue to be informed about DRS recommendations when the hosts on the recovered site are online, but can now wait until vSAN has fully resynced the virtual machine components. DRS can then be changed back to fully automated mode, which will allow virtual machine migrations to take place to conform to the VM/Host affinity rules.
For Storage DRS (if applicable), this should be configured in manual mode or partially automated. This enables human validation per recommendation and allows recommendations to be applied during off-peak hours. Note that the use of I/O Metric or VMware vSphere Storage I/O Control is not supported in a vMSC configuration, as is described in VMware KB article 2042596.
Multipath selection
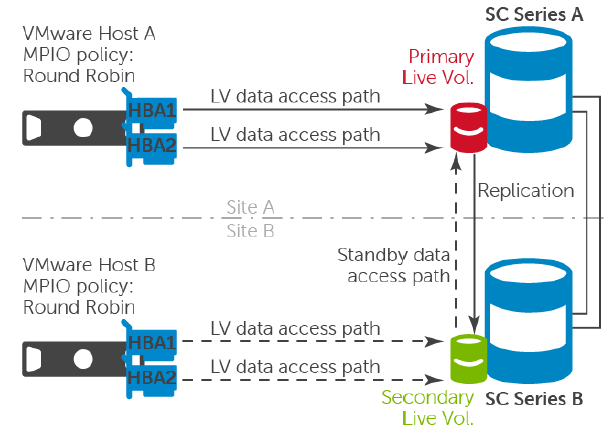
For block-based storage, multi-path policies are critical for the stretched cluster.
In a uniform configuration, for example for Dell SC array with Live Volumes, you must use a fixed path to ensure the locality of the data:

For non-uniform configuration, the data locality is implicit, so you can maximize (local) paths usage and distribution with round robin:
Be sure to check specific storage vendor best practices or reference architecture.
Myths
Disaster recovery vs. disaster avoidance
Disaster Avoidance, as the name implies, is the process of preventing or significantly reducing the probability that a disaster will occur (like for human errors); or if such an event does occur (like for a natural disaster) that the effects upon the organization’s technology systems are minimized as much as possible.
The idea of disaster avoidance provides better “resilience” rather than good recovery, but to do so, you cannot rely only on infrastructure availability solutions, that mostly are geographically limited to a specific site, you need to look also at how to provide a better application availability and redundancy in the wake of foreseeable disruption.
Multi-datacenter (or multi-region cloud) replication is one part, the second part is having active-active datacenters or have applications spanned between the multiple sites that provide service availability.
Most of the new cloud-native applications are designed for this scenario. But there are also some examples of traditional applications with high availability concepts at the application level that can work also geographically, like: DNS services, Active Directory Domain Controllers, Exchange DAG or SQL Always-On clusters. In all those cases one system can fail, but the service is not affected because another node will provide it. Although solutions like Exchange DAG or SQL Always-On rely internally on cluster services, usually applications designed with high availability solutions use systems loosely coupled without shared components (except of course the network, but it can be a routed or geographical network).
An interesting example of the infrastructure layer could be the stretched cluster.
Disaster recovery vs. Stretched cluster
Although stretched cluster can be used also of disaster recovery and not only for disaster avoidance, there are some possible limitations on using a stretched cluster also as disaster recovery:
- Stretched cluster can’t protect you from site link failures and can be affected by the split-brain scenario.
- Stretched cluster usually works with synchronous replication, that means limited distance, but also the difficult to provide multiple restore point at different timing.
- Bandwidth requirements are really high, to minimize storage latency. So you need not only reliable lines but also larger.
- Stretched cluster can be costlier than a DR solution, but of course, can provide also disaster avoidances in some cases.
In most cases, where a stretched cluster is used, then there could be third site acting as a traditional DR, using in this way a multi-level protection approach.

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
