








VMware vSAN is a powerful hyperconverged solution, but sometimes still lack of some information or usability. In most cases the health engine is working well and automatically, but in other case it needs your attention and manual operation.
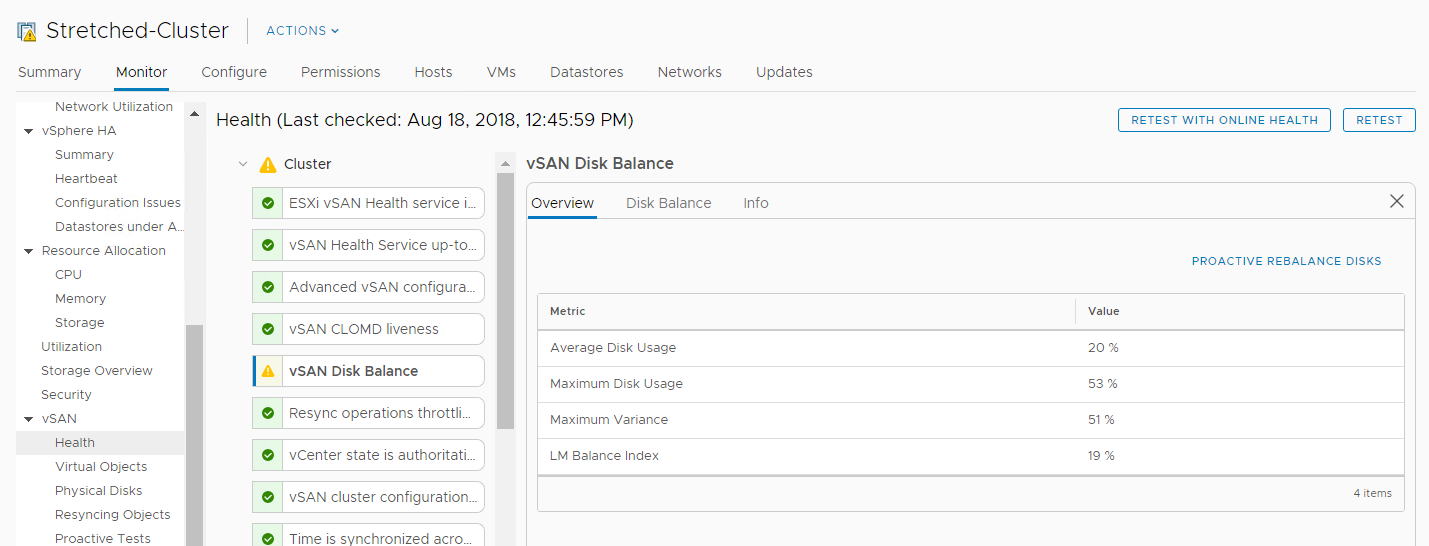
One example is the vSAN Disk Balance alarm that sometimes happen in your cluster and bring your healt status no more “green”.
This warning just indicate that that the cluster is imbalanced and there are disks that are high on space usage while others are very low, that potentially can make your cluster no more optimal.
You need to manually run a proactive rebalance that initiates a rebalance of the objects in a vSAN cluster. The VMware KB 2149809 (vSAN proactive rebalance) describe this case in the detail.
If disks report this kind of warning in the vSAN health check you have vSAN disks unbalanced:
Running a manual rebalance may be necessary when your vSAN cluster is imbalanced. This operation moves components from the over-utilized disks to the under-utilized disks.
Starting with vSAN 6.5 it’s possible run a disk relance direcly from the UI (with vSAN 6.7 also with the vSphere Client) by clicking on the “Proactive rebalance disks”. A confirmation will appear:
 From the UI you cannot track properly the progress… you will see 5% but then seems to be stopped… wait… and hope… it can take hours or sometimes also days!
From the UI you cannot track properly the progress… you will see 5% but then seems to be stopped… wait… and hope… it can take hours or sometimes also days!
Manually or automatically?
But why manually… It should be automatically as written in Cormac blog post?
The reason it’s related to the I/O impact of this operation: because cluster rebalancing generates substantial I/O operations, it can be time-consuming and can affect the performance of virtual machines.
By default, vSAN will try to do a proactive rebalance of the objects as the disks start hitting certain thresholds (80%). There are instances, during failures/rebuilds, or even when organic imbalance is discovered, where administrators may trigger a proactive rebalance task.
This post provide useful info: https://cormachogan.com/2015/04/22/vsan-6-0-part-9-proactive-re-balance/
You may also not see any progress at all for the first 30 minutes. This is because VSAN wants to wait to make sure that the imbalance persists before it attempts to move any objects around. After all, the rebalance task is moving objects between disks/nodes, so copying data over the network will take resources, bandwidth and time; so plan accordingly if you must rebalance.
Notice that if your disks are balanced, the button is greyed out to avoid unnecessary object “shuffling”.
How disks usage is monitored?
VMware vSAN checks the used capacity of the physical disks using this formula:
used_capacity_of_this_disk / this_disk_capacity
and compares it to the used capacity of the least used disk:
used_capacity_of_least_full_disk / least_full_disk_capacity
In other words, a disk is qualified for proactive rebalancing only if its fullness exceeds the fullness of the “least-full” disk in the VSAN cluster by more than the variable threshold. The rebalancing process also needs to wait until the time threshold is met. In other words, the variance threshold must be met for this amount of time.The time threshold value, by default, is 30 minutes.
How monitor the rebalance?
As written the UI does not help to much to see at which point is the operation (little better with latest released).
On option could be use the rcv command that can also help to check the disks usage and was the only was prior to vSphere 6.5.
The command to check the status is:
> vsan.proactive_rebalance_info 0 Proactive rebalance is not running!
root@vcenter1 [ ~ ]# rvc [email protected]@localhost
Install the “ffi” gem for better tab completion.
password:
Welcome to RVC. Try the ‘help’ command.
0 /
1 localhost/
> vsan.proactive_rebalance_info 0
Expected ClusterComputeResource but got RVC::NullConnection at “0”
> vsan.proactive_rebalance_info
missing argument ‘cluster’
> vsan.proactive_rebalance_info
missing argument ‘cluster’
> cd localhost/
/localhost> dir
invalid command
/localhost> ls
0 SP-ING (datacenter)
1 FIB (datacenter)
/localhost> cd SP-ING/
/localhost/SP-ING> ls
0 storage/
1 computers [host]/
2 networks [network]/
3 datastores [datastore]/
4 vms [vm]/
/localhost/SP-ING/computers> vsan.proactive_rebalance_info 0
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-sp1.vmware.local …
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-sp2.vmware.local …
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-sp3.vmware.local …
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-sp4.vmware.local …
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-ing1.vmware.local …
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-ing2.vmware.local …
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-ing3.vmware.local …
2018-08-19 09:38:33 +0000: Retrieving proactive rebalance information from host esxi-ing4.vmware.local …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-sp2.vmware.local (may take a moment) …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-ing4.vmware.local (may take a moment) …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-sp1.vmware.local (may take a moment) …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-sp3.vmware.local (may take a moment) …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-ing2.vmware.local (may take a moment) …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-sp4.vmware.local (may take a moment) …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-ing3.vmware.local (may take a moment) …
2018-08-19 09:38:34 +0000: Fetching vSAN disk info from esxi-ing1.vmware.local (may take a moment) …
2018-08-19 09:38:37 +0000: Done fetching vSAN disk infos
Proactive rebalance is not running!
Max usage difference triggering rebalancing: 30.00%
Average disk usage: 21.00%
Maximum disk usage: 31.00% (30.00% above minimum disk usage)
Imbalance index: 20.00%
No disk detected to be rebalanced
Using rvc you can also manually start a new rebalance:
> vsan.proactive_rebalance -s 0 Proactive rebalance has been started!

