








Aparavi has announced major enhancements to its Active Archive℠ platform, delivering improved resource management and operational efficiency, as well as enhanced insight and management of archived data.
Aparavi’s Active Archive SaaS solution delivers intelligent multi-cloud data management to organizations grappling with large volumes of unstructured data.
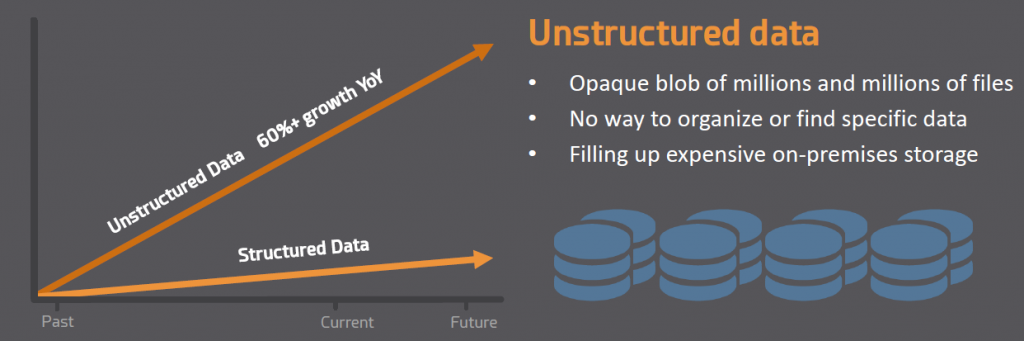
Launched May 2018, Aparavi Active Archive is being embraced by organizations grappling with the huge volume of unstructured data retained for purposes such as compliance, historical reference, and business reporting/analytics. Aparavi’s intelligent multi-cloud data management provides the ability to actively manage data for long-term policy-based retention, open access, and re-use, while providing an easy path to multi-cloud adoption by reducing secondary storage growth by up to 75% with a simple, efficient SaaS-based Active Archive.
Their patent-pending data pruning technology reduces backups and secondary storage growth, while our true multi-cloud agility removes vendor lock-in and provides economic advantage.
Architected for the cloud, Aparavi is a completely new approach to solving the challenge of massive unstructured data growth, giving organizations the control they need to intelligently keep their data now and forever. Our Software-as-a-Service solution allows you to start small and scale to petabytes, with pay-as-you-go based on usage.

Aparavi’s Three-Tier Architecture
Using a three tiered architecture allows for near CDP style checkpoints, file by file snapshots, and archives. A file base snapshot of each source node is done based on the defined data selected, and stored on the software appliance, then CDP style checkpoints can be configured as a temporary recovery cache at the source itself.
New features include:

- Direct-to-cloud for improved resource management and operational efficiency -Direct-to-cloud provides the ability to archive data directly from source systems to the cloud destination of choice, with minimal local storage requirements. This substantially decreases the on-premises storage and compute requirements, greatly simplifies set up, and removes the need for a dedicated software appliance. On-premise storage resources do not need to be allocated for data staging, and data can be pushed directly to one or more cloud destinations.
- Next-generation data classification and tagging for better management and simplified access –
- Updated classification and tagging capabilities make it simple to classify data based on individual words, phrases, dates, file types, and patterns. Users can easily identify and tag data for future retrieval purposes such as compliance, reference, or analysis. Examples would be classifying all PHI (Personal Health Information), PII (Personally Identifiable Information), or legal files. Aparavi includes pre-set classifications of “confidential,” “legal,” and PII; ad hoc additions are easily created with a few simple steps.
- Next generation search for greater insight and access –
- An intuitive query interface allows users to find any data wherever it resides in the archive, whether on-premises or in one or multiple clouds, without having to know the location. Aside from “Google-like” full-content search by words, phrases, or patterns files can be searched by their metadata, including classification, tag, date, file name, file type, or optional wildcards. Results are returned intelligently in context for easier identification, and are viewed in the cloud or storage destination without retrieving until requested. Current file types supported include any text file, PDF, and modern Microsoft Office formats. Future updates will add images and older Microsoft Office formats.
- Enhanced multi-cloud management and bulk-data migration –
- Additional cloud destinations have been added and together include AWS, Backblaze B2, Caringo, Cloudian, IBM Cloud, Microsoft Azure, Oracle Cloud, Scality, and Wasabi. Aparavi’s multi-cloud support enables users to select the best destination for their data, and adds support for new bulk migration to move data easily from one location to another, including on- or off-premises. Users can now take advantage of changing cloud economics at any time.

