








This is the second part of a set of posts realized for StarWind blog and focused on the design and implementation of a ROBO infrastructure. See also the original post and the first part.
Design areas and technologies
In the previous post, we have explained and described business requirements and constraints in order to support design and implementation decisions suited for mission-critical applications, considering also how risk can affect design decisions.
Now we will match the following technology aspects to satisfy design requirements:
- Availability
- Manageability
- Performance and scaling
- Recoverability
- Security
- Risk and budget management
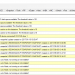
All those aspects must be matched to each layer of the technology stack including:
- Workloads and applications
- Virtualization
- Compute and host
- Storage
- Networking
Availability aspects
This is probably the most important aspect to consider for a ROBO scenario because can have a direct impact on the business. Of course, it must be balanced with the budget constraints.
Availability of a system or a service is typically measured as a factor of its reliability or just in a number or nice of its availability level.
Also, if a remote office may be small compared to an enterprise or corporate office, the business requirement on the availability could be high, depending on the workload type and the business requirements (that can define some workload as business critical).
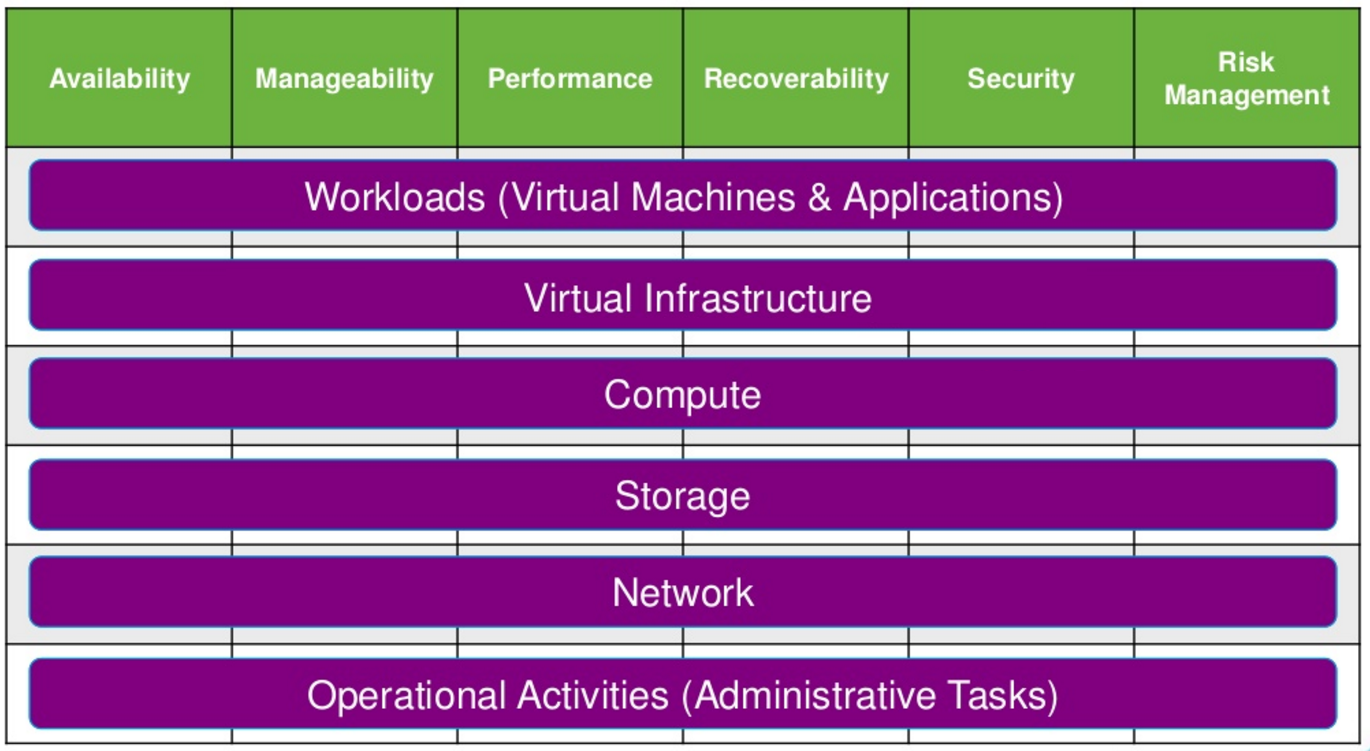
In ROBO scenario a reasonable availability level could be between 99% and 99,99%, but there are some workloads that may require the higher level (or other that are not critical at all).
Note that there are different categories of availability
- High availability: the service or application is available during specified operating hours with no (relevant) unplanned outages. Usually, ROBO falls in this one.
- Continuous operations: the service or application is available 24 hours a day, 7 days a week, with no scheduled outages.
- Continuous availability: the service or application is available 24 hours a day, 7 days a week, with no planned or unplanned outages.
Workloads
As written business requirements and type of application or service drive the availability decision. Depending by the business impact of the workload you may need the high level of availability.
But how you can increase the availability level of a service or application?
Are the applications designed to fail and be high available? In this case, the low technology layers may be not so relevant because they can just fail and the application will handle it. Of course, this does not mean that you need creepy systems and infrastructure, but with standard solutions with reasonable reliability, you can be fine.
Applications build with high availability concepts (at the application level) are, for examples, DNS services, Active Directory Domain Controllers, Exchange DAG or SQL Always-On clusters. In all those cases one system can fail, but the service is not affected because another node will provide it. Although solutions like Exchange DAG or SQL Always-On rely internally on cluster services, usually applications designed with high availability solutions use systems loosely coupled without shared components (except of course the network, but it can be a routed or geographical network).
Another example of a service that can handle local failures is the Microsoft DFS for network shares: if a primary link fails (because the server with the share fails), clients can point to a secondary share.
But usually applications (especially legacy applications) just require and infrastructure that does not fail or has high availability level at more layers or uses solutions like high availability clusters or fail-over clusters (or, for some type of workload, also load balancing clusters).
Cluster high available
A failover cluster is a group (cluster) of servers (or nodes) that work together to provide an infrastructure high availability for applications and services. If one of the servers fails another server in the cluster can take over its workload with a minimal downtime (this process is known as failover).
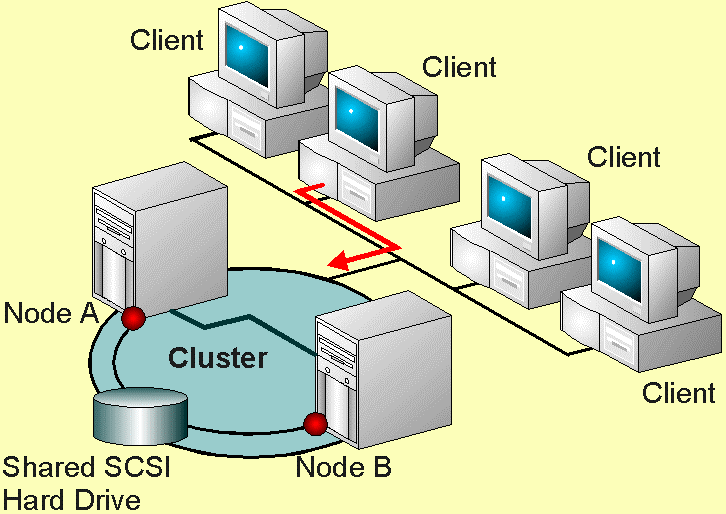
Actually, there are the different ways to implement an HA cluster, but in most case, it’s implemented at guest OS level (for example using Microsoft Failover Cluster service) or at virtualization level (see next paragraph).
The first approach it’s more complicated and limited at the service level, but can provide a better availability level and can handle not only the host failure but also the OS and the application failure.
Virtualization
Depending on the hypervisor there are different solutions, at this level, to increase the availability level.
At least all enterprise level virtualization solutions provide two different type of services:
- VM HA: for restart VMs on other hosts when a physical host fails, useful for unplanned events.
- VM live migration: usable to move a running VM from one host to another in case of planned events.
Of course, you have to consider clearly which type of failure can the HA solutions identify and manage (for example storage loss from one node, network partition, ….), but also consider the availability solutions for the virtualization infrastructure (like for the management services or server).
For VMware there are different solutions, depending on the edition of ESXi, that can improve availability:
- vSphere HA is a solution that can handle host failure or also guest OS failure (using VM HA) or guest application failure. Can provide an availability level of 99% or more.
- VMware FT can handle host failure but without the service interruption (providing better HA availability, more than 99,99%), but with more limitation on the size of the VM that can be protected and the required resources.
- VMware vMotion is the well now service to migrate the VMs across hosts (and starting from vSphere 6.0, also across vCenter or sites).
- VMware Storage vMotion is the dual function of vMotion used to migrate VMs across storage (useful to handle planned maintenance or downtime at storage level).
Compute
A single host could be built with good components, reliable solutions (like ECC RAMs) and redundant parts (like RAID disks or double power supply). But still can fail (or can fail some other layer) and for this reason, it’s not enough to provide a good availability level.
In order to have an availability level around 99% and 99,9% more nodes are required to an HA cluster function at virtualization level (or also at the guest level to provide a better availability level or more control at service level).
At least two nodes are required with VMware HA and VMware vMotion features (using VMware vSphere). But how many nodes? It depends also on performance aspects, but for most ROBO scenarios two physical nodes could be really enough.
Storage
Storage should have enough redundancy and good availability level (99,95% or more). But most important it must provide high resiliency and integrity of the data. Data protection solutions must be planned well in case of data failure or loss of data availability.
Storage could be local (not shared or hyperconverged) or external (shared across nodes), but more considerations on the storage topologies will be covered in the next post.
Network
Networking in a remote branch office could not have a good redundancy and this could be a risk (especially if it also used as a back-end for services like storage replica or cluster heartbeat).
Usually, in a small office you will found a single switch with limited throughput (and maybe with still ports at 100 Mbps) and for sure not full rate.
Services that requires high bandwidths and/or low latency must be handled on the dedicated network infrastructures. For a two physical nodes infrastructure, an interesting option is a direct connection between network cards.
Recoverability aspects
 Recoverability refers to the ability to restore your services to the point at which a failure occurred. It can be strictly related to the availability aspects, but usually, you are going to cover events and cases where HA solutions cannot help.
Recoverability refers to the ability to restore your services to the point at which a failure occurred. It can be strictly related to the availability aspects, but usually, you are going to cover events and cases where HA solutions cannot help.
It’s more related to business continuity and disaster recovery aspects. And with all the data and system protection solutions that you have to implement.
Recoverability does not care about the different layers that you have, it requires that you recover the services (also on a different stack).
The ability to recover quickly from a system failure or disaster depends not only on having current backups of your data but also on having a good plan for recovering that data and the related services.
There will be a dedicated post on data protections aspects.
Manageability aspects
After the business continuity aspects described previously, manageability could be one of the most important requirements for a ROBO scenario (or at least have a huge impact on the operational costs).
As written, one of the big risks in ROBO scenario is the lack of local IT staff: usually, all the IT people are located in the main office and moving them to a remote office could be cost.
For this reason, remote management is a must and systems and services monitoring should be centralized. Management also could be centralized, but it’s not mandatory because it could be enough a remote management.
Management could also consider the physical and hardware layer for servers (using ILOE, iDRAC of other remote management features) and other devices (using out-of-band features or simple standard remote management). The ability to manage not only the remote console but also the power state of a server should be a must in order to have a full remote management capability. The same consideration should be applied at the storage layer.
Note that central management could be limited by geographical network bandwidth and latency that could be not enough to provide this capability. Also, central monitoring could be limited by those aspects, but usually is less impacted. For example, a central vCenter Server may have continuous remote host disconnections (and reconnections) or the usability of itself could be seriously impacted.
Using VMware vSphere as an example of virtualization platform there are several types of vCenter deployments with the different types of manageability:
- Single (and centralized) vCenter Server, but in this case (as written) network bandwidth and latency should be considered carefully. Also, it requires a Standard edition for vCenter and notes that (starting with vSphere 5.x) it cannot manage remote Essential or Essential Plus ESXi.
- Multiple vCenter Server in Linked mode: one server in each remote office using linked mode to have a single pane of glass for management. Again, it requires a Standard edition for vCenter and it cannot manage remote Essential or Essential Plus ESXi.
- Multiple vCenter Server: each remote office is just an independent (from the management point of view) “silo”. In this case, management could be more complicated, but it’s possible to use also Essential or Essential Plus bundles.
License aspects are strictly related to features but also costs and budget constraint. More will be discussed in next post.
For monitoring, there are a lot of tools and most are able to aggregate more independent vCenter Server and provide (for the monitor point of view) a single pane. OpenSource solutions can also be considered.
Backup related aspects (including central management and monitoring options) will be discussed in a dedicated post.
Performance and scaling aspects
 Usually, performance could not be a huge constraint in a ROBO scenario. As written two hosts could be enough to provide a reasonable availability level, but in the most cases, all workloads (of a remote office) can just run on a single physical host.
Usually, performance could not be a huge constraint in a ROBO scenario. As written two hosts could be enough to provide a reasonable availability level, but in the most cases, all workloads (of a remote office) can just run on a single physical host.
More important design a good solution for a remote office that can use as a reference architecture (or building block) for all (or most) other remote offices in order to scale this solution to the entire infrastructure.
Networking
For local networking, in most case, SMB targeted 1 Gbps switches could be the best solution for a remote office (note: don’t rely on 10 Gbps uplink ports for host connectivity because is mid-level switches those ports may be not designed for end systems).
In some cases, (like hyperconverged storage) you may need more network speed, but with a simple two nodes configuration, “cross” cable could(/should) be an option instead of buy faster (and costlier) switches.
And what about the geographical network? What is the minimum bandwidth to the main office? As described previously, central management could be impacted by the available bandwidth.
But you should also consider other aspects like backup, monitoring and, of course, the required bandwidth for your services. In most cases, at least 1 Mbps symmetrical could be enough (or the good starting points).
More important for WAN connection are the network latency and the reliability of the network: those can limit the possible choices for central management but also other services and solutions.
Storage
From the performance point of view, storage is usually the critical aspect. But in ROBO scenario, in each remote office the number of workloads are limited (several times just a couple of VMs).
Flash disks could be an option, but not necessary in most cases, because a single spinning disk (at 10k RPM) just run 2/3 medium VMs with reasonable performances. Of course, you have to provide the right availability and resiliency level, as also the right capacity, for this reason, more disks are required.
Read cache could be enough to improve the performance at host level, but again, in most cases is not required at all.
In the next post, we will discuss more on different storage choices and options.
Compute
In ROBO scenario CPU is (usually) not a limit and with modern processors, one single socket has enough cores (10 cores are actually really affordable) to run required workloads. Note that the number of sockets and cores may impact the licenses costs (we will discuss more in the next chapter).
More critical could be the RAM that should be enough: in a two nodes scenario, all critical workloads must run on a single host, so it should be designed to this case. Note also that hyperconverged solutions require more RAM (that must be planned carefully).
Security
Security in ROBO scenario is usually the least considered aspect. Not because it’s not important or relevant, but just because people forget it at the remote offices (usually there is more attention at the central office).
Considering the lack of local IT staff in a remote office, but also the limited physical security level, this could be one of the major risks!
For some services, you can apply specific solutions (for example RODC for Active Directory Domain Controllers), but generally, data encryption should be considered. Different approaches could be used depending by the layer:
- Storage level: Self-encrypting drives (SED) can be an option, but usually it costly
- Virtualization level: starting for vSphere 6.5 there is a new function for VM encryption (in Windows Server 2016 Hyper-V has a similar feature called Shielded VMs). There also third party solutions to achieve this result.
- Guest level: Windows Server has BitLocker feature to encrypt the entire volumes (or also single file encryption). Linux distributions have a similar feature to encrypt the entire filesystem.
In all those cases, keys management it’s really important, but encryption could impact also other aspects like performance (expect SED, other solutions can impact the storage performance for a ROBO scenario may be not so relevant) or also recoverability (or data protection).
Licenses aspects
 For ROBO scenario minimizing the license cost of each office could be a really important requirement.
For ROBO scenario minimizing the license cost of each office could be a really important requirement.
VMware vSphere ESXi licenses that are most interesting for remote offices are the ROBO SKU that is sold per VM (25 VMs SKU). ROBO advanced is around 180€ per VM that is cheaper (for few VMs) compared to ESXi Standard (around 1000 € for one socket) or also the Essential Plus Kit (less than 4000€ for 3 hosts and 6 sockets). ROBO license it’s independent by the number of hosts or sockets or cores, but please notes that each VMs count a license, including management VMs (like VSA or other VA).
Windows Server licenses is based per socket (and starting with Windows Server 2016 also with a limit on the total number of cores) so you have to take care of your processors. For the editions, with just a couple of VMs, Windows Standard edition could be considered to limit costs.
Storage licenses depends on the type of storage: it can be included in the cost of storage itself, but for software-based storage like VSAN or other VSA based storage it can be licensed in the different ways: per capacity (like several VSA solution), per socket (like VSAN) or also per VM (like VSAN for ROBO).
For VMware VSAN, again, the ROBO SKU could be interesting for a small number of VMs in each remote office (around 500€ per VM), compared to the other license option (starting from 2500€ per socket for the Standard edition).
Backup solutions native for virtualization environment are usually licensed per host socket.
In the next post, we will discuss which type of infrastructure can be used at remote office side, matching the business and technical aspects described previously.
Related materials:

