

This post is also available in: Italian
Reading Time: 5 minutesNote: the company has closed all operations on January 2018.
Primary Data emerged from stealth November 19, 2014 and I was lucky enough to met them one year ago (see #ITPT 14 Report – Primary Data) and learn about their interesting vision of storage virtualization. Primary Data’s product has been officially announced during VMworld US 2015.
Its headquarter is in Los Altos, CA with offices around the world and currently employs about 80 staff worldwide and with over $60 million in venture capital raised to date.
Their vision is quite simple: transforming datacenter economics with Data Mobility through Data Virtualization.
During the last IT Press Tour #17 I’ve got the opportunity to met then after one year, and see what is changes during this time. David Flynn, (CTO at Primary Data) explain us his view and the difference between Data and Storage Virtualization, and how their solution is unique.
Primary Data target is really clear and defined: at this time only Enterprise company that need SDS on existing (non hyperconverged) storage.
They start from a simple fact: different storage type naturally create data silos and you may need more data mobility, more than the one provided by Storage vMotion or similar features. You can have this mobility at storage level, but only using the same vendor and only on some products.
Of course you can put at the top a “storage virtualization layer” like DataCore or FalconStor, but this is a new layer useful in some cases (for example if you have storage with very few data services) but also potentially a bottleneck or an increased degree of complexity. And storage virtualization is not data virtualization.
Data virtualization delivers dynamic data mobility according with some optimizing criteria like performance, capacity and costs:
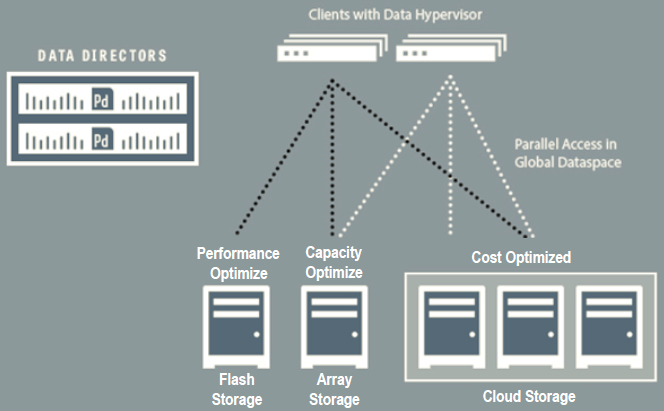
It also provide a single global dataspace to access all the storage resource, including DAS, SAN, NAS and object storage:
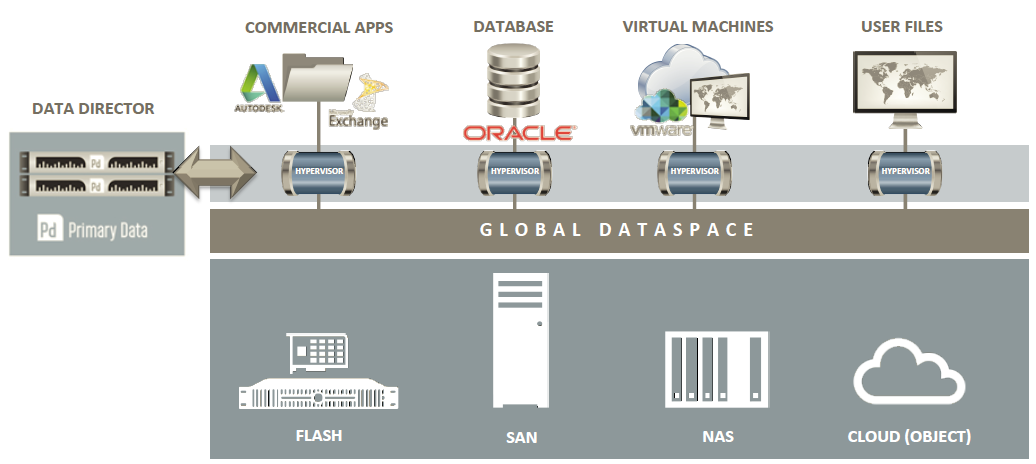
The interesting aspect is that this approach could also be extend to data protection, considering durability, availability, priority, recoverability, and security parameters and requirements.
As you can notice, Primary Data has a dedicated control plan based on a redundant configuration of Data Director managed by a DataSphere manager. The big news, compared to the past year, is the availability also of virtualized controllers and not only physical controllers (like was at the beginning).
Data path is the traditional data path plus a client (an “agent” installed on each access node), in this way each client (usually a server connected to the storage) ask to the data directors how reach the storage (and which storage), the data director will explain at the agent how, and at this point the client can access and work with the storage without talk again with the data director. Controllers works as a redirector to build the first “connection” to the right storage. All the agents are stateless!
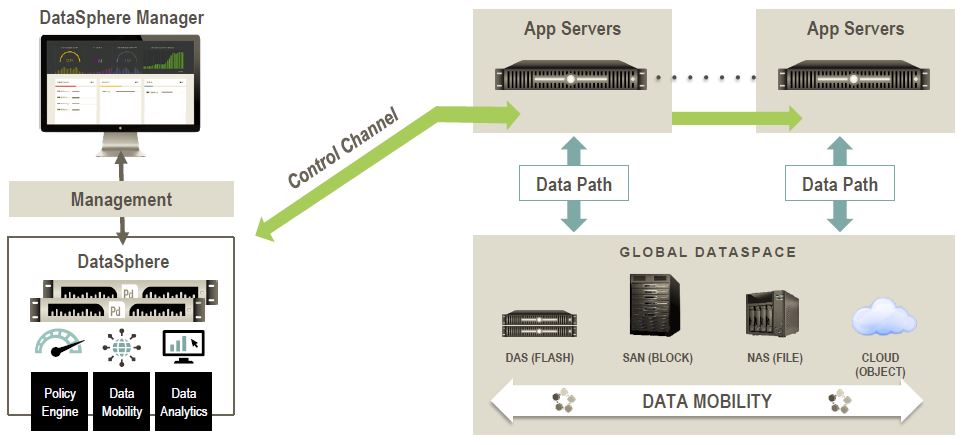
Those client should be native for performance reason and actually Linux is the primary platform. On Windows/Hyper-V the client/agent is just a filter driver (in Windows the SMB protocol will be used instead of NFS protocol that is the default one used by Primary Data). For VMware vSphere, at this point the client is just a virtual appliance, but they are working to transform it as a filter using the new VAIO framework. For legacy environment there is also a dedicated agent (in a Linux machine) called “portal”.
So the agent implementation is still a work in progress, but on the other side the control plane is already in an interesting state with several features including the objectives (and smart objectives) to automate decision-making in order to maximize efficiency and reach the desired goals. Mapping between objectives and the real storage capabilities is something complex, but the result is really effective: for example to demote a storage you have only to set the target objects durability and availability to zero and wait until the data are moved. Of course you can set the performance limit or the priority for each data movement.
Will be also interesting see when will be implemented also some data services like data availability. As written you can handle also local storage (DAS) and it’s possible redirect the access to this storage also from other client (because it’s exported as a NFS share). By adding also an availability service you can transform local storage to shared storage.
In conclusion, Primary Data has a unique data virtualization solution that still need some implementation. But they strategy seems quite clear and prioritized by those steps and target:
- First the virtualization with VMware vSphere 6.0 and with Virtual Volumes
- Second the huge scale-out NAS (to become an alternative to Isilon)
- Thirth the data migration scenario
- And then backup/restore / Archive / Cloud Gateway
Disclaimer: Condor Consulting Group has invited me to this even and they will paid for accommodation and travels, but I am not compensated for my time and I’m not obliged to blog. Furthermore, the content is not reviewed, approved or published by any other person than me.

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
