

This post is also available in: Inglese
Reading Time: 7 minutesPrimary Data è un’azienda molto recente emersa della modalità “stealth” solo il 19 November 2014 e che ho avuto modo di incontrare poco dopo, giusto un anno fa (vedere #ITPT 14 Report – Primary Data). Il loro prodotto (anche se all’epoca era più una vision) di data virtualization è stato poi ufficialmente annunciato durante il VMworld US 2015.
L’azienda ha la sede centrale in Los Altos (nella solita Silicon Valley) con uffici sparsi in tutto il modo e più di 80 impiegati. Ma l’aspetto più saliente è che ha avuto più di $60 milioni in venture capital.
La loro vision è chiara e volendo anche semplice: trasformare il datacenter (in particolare la parte di storage) introducendo innovative funzionalità di data mobility tramite un particolare approccio di data virtualization.
Durante l’ultimo IT Press Tour #17 ho avuto modo di ritornare in questa azienda (esattamente un anno dopo) e scoprire quali sono state le novità in questi mesi, direttamente dalla voce di David Flynn (CTO di Primary Data).
Il primo punto chiave è che Primary Data ha un target molto chiaro di aziende (e, vedremo alla fine, anche di user case): al momento solo le Enterprise che richiedono storage con funzionalità di tipo SDS (Software Defined Storage), ovviamente partendo da una base già esistente (e non di tipo hyperconverged).
Il secondo punto chiave (in parte già chiaro un anno fa, ma che vale la pena ribadire) è la differenza tra Data e Storage Virtualization.
Il punto di partenza è identico: differenti tipi di storage comportano l’inevitabile formarsi di silo e limitano la data mobility. Tralasciando se i silo sono buoni o cattivi (personalmente non ritengo che abbiano sembre un’accezione negativa), è chiaro che la mobilità dei dati può parzialmente essere risolta da soluzioni a livello di hypervisor (come lo Storage vMotion nel caso di VMware) o soluzioni di basso livello fornite dallo storage (ma in questo caso ci si vincola ad un tipo di storage vendor e spesso ad un tipo particolare di modello di storage).
Le soluzioni di “storage virtualization” (come, ad esempio, DataCore o FalconStor) aggiungono un livello di astrazione che svolge da tramite per qualunque operazione allo storage. Sono sicuramente soluzioni interessanti, in alcuni scenari (dove ad esempio bisogna migrare lo storage o lo storage non fornisce data service evoluti). Ma è comunque un livello di complessità in più e un potenziale collo di bottiglia.
Le soluzioni di “data virtualization” lavorano in modo diverso, un po’ come fa un redirector, che si limita ad indicare qual è lo storage corretto da utilizzare. Tipicamente cercando di ottimizzare uno (o più) di questi parametri: prestazioni, capacità e costi.
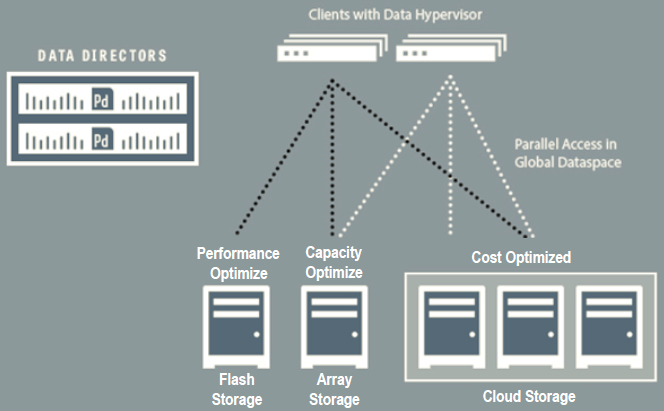
Tutti gli storage vengono aggregati sotto un unico global dataspace che permette la gestione unificata di storage di tipo DAS, SAN, NAS e object storage:
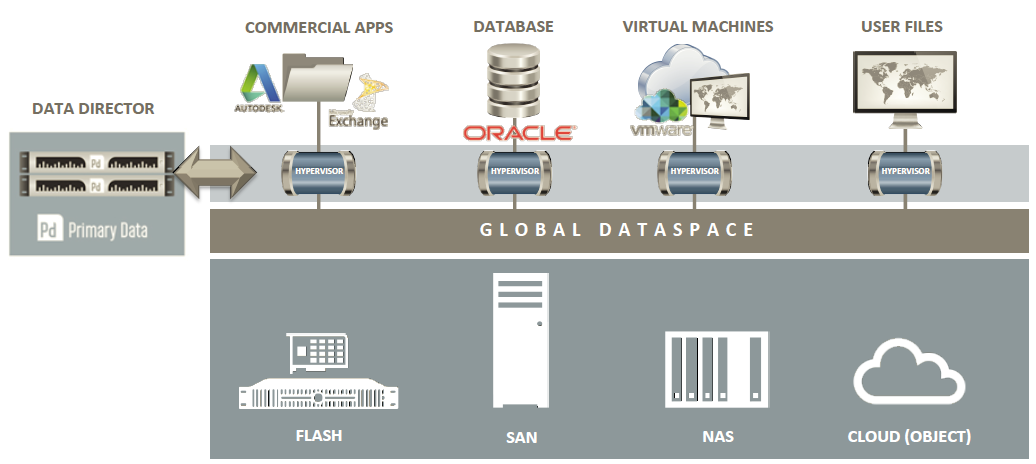
L’aspetto interessante di questo approccio è che risulta facile estendere i criteri di scelta a criteri come, ad esempio, la data protection, considerando aspetti di affidabilità, disponibilità, priorità, recoverability e sicurezza.
Come si può notare dagli schemi precedenti, la soluzione di Primary Data ha un piano di controllo gestito da due controller (chiamati data director o DataSphere controller) in configurazione ridondata. Rispetto a quanto annunciato l’anno scorso, finalmente è disponibile anche una versione sotto forma di virtual appliance e non solo la versione fisica.
Il data path è, di fatto, quello normale, pilotato però da un agente o client (installato in ciascun sistema che deve collegarsi allo storage). Il client chiede al data director quale percorso usare (in base ai criteri visti in precedenza) e da quel momento in poi non dovrà più utilizzare il controller, ma l’accesso sarà diretto (a meno di migrazione dei dati o nuovi criteri di ottimalità). Notare che tutti gli agenti sono stateless e relativamente semplici!
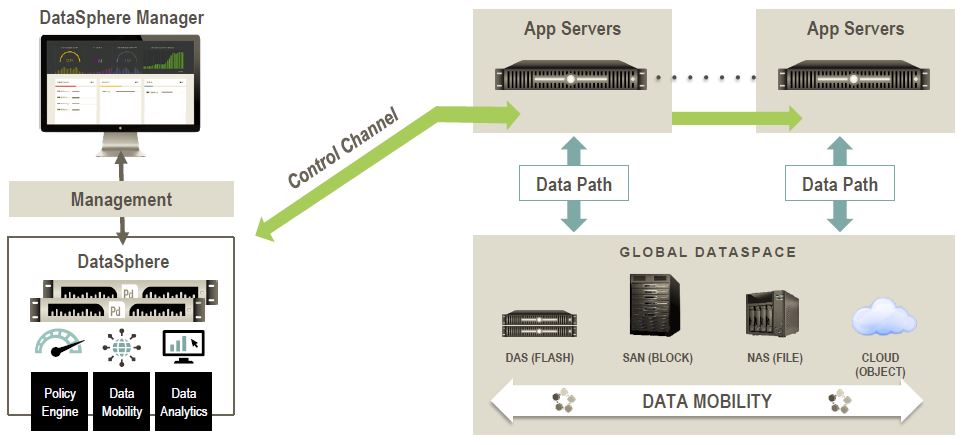
Al momento la piattaforma di riferimento per questi agenti è Linux (e potrebbe non stupire se prima o poi diventasse mainstream nel kernel di Linux, come successo ad esempio con parte delle VMware Tools o dei componenti di integrazione di Hyper-V). Ed è la parte già pronta.
Su Microsoft Windows e quindi anche su Hyper-V l’agente è in realtà un filter driver e il protocollo di riferimento ovviamente diventa SMB, anziché NFS.
Per VMware vSphere, al momento l’implementazione dell’agente è sotto forma di virtual appliance, ma stanno lavorando per adattarlo al nuovo VAIO framework e farlo diventare “nativo”.
Per ambienti legacy esiste un agente separato (in una macchina Linux) raggiungibile via rete, chiamato portal.
Quindi c’è ancora molto lavoro da fare sulla parte agenti, ma qualcosa è già pronto (anche se non ottimale). Diverso è invece quello che riguarda il control plane che è già in fase molto evoluta, includendo funzionalità interessanti di gestione degli “obiettivi” per automatizzare criteri e decisioni in termini di efficienza delle varie metriche.
Il risultato è decisamente interessante e permette di svolgere anche operazioni di manutenzione con semplici criteri di alto livello: ad esempio decomissionare uno storage è semplice, basta impostare come target object durabilità a 0 e disponibilità 0. Ovviamente è possibile impostare un limite alle prestazioni dedicati al data movement, come pure impostare la priorità di queste operazioni.
Sarà anche interessante vedere come implementeranno alcuni data service (e quali implementeranno), in particolare quelli relativi alla data availability: per ora la soluzione non effettua repliche dei dati, ma può esporre uno storage locale (DAS) come storage condiviso NFS. Abbinando una funzione di ridondanza dei dati potrebbe diventare molto interessante.
In conlcusione, Primary Data ha un approccio del tutti unico alla data virtualization, ma per alcuni aspetti tecnici è ancora un work in progress. La loro strategia è comunque ben delineata e prevede diversi passi e priorità nel loro go to market:
- Prima la virtualizzazione con VMware vSphere 6.0 e soprattutto con i Virtual Volume, come modalità di accesso e un universal VASA per esporre i vari obiettivi. Seguirà poi un’implementazione per vSphere 5.5 (anche se secondo me non vedrà mai veramente la luce, un po’ perchè si sarà imposta la versione 6.0, un po’ per le complicazione del back-port).
- Il secondo target sono i scale-out NAS di grosse dimensioni (tipo Isilon)
- Il terzo scenario sarà la migrazione dei dati (anche se secondo me questo caso d’uso potrebbe essere uno dei più interessanti e non mi stupirebbe veder scalare posti nelle priorità dell’azienda)
- Solo alla fine si concentreranno sullo storage secondario, come quello per i backup/restore, per l’archiviazione, … con le varie funzionalità anche di Cloud Gateway
Disclaimer: Sono stato invitato a questo evento da Condor Consulting Group che ha coperto i costi per il viaggio e l’alloggio. Ma non sono stato ricompensato in alcun modo per il mio tempo e non sono in obbligo di scrivere articoli riguardo all’evento stesso e/o gli sponsor. In ogni caso, i contenuti di questi articoli non sono stati concordati, rivisti o approvati dalle aziende menzionate o da altri al di fuori del sottoscritto.

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
