



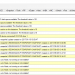





In an old post about storage architectures is described in a simple way some basic concepts, including the scale-in (or scale-up) vs. the scale-out approach. They are different approaches in scaling with different implications.
Unfortunately there is a simple an well accepted definition on what is a scale-out storage is (or not is): some are limited in specific contests (like this one only for NAS or this SNIA tutorial still applied to a NAS storage), other are too much vendor specific.
But usually a scale-out storage imply:
- Multi-device (or multi-array) storage systems (aggregated in a pool of resources)
- Possibility to scale both in capacity and in performance
- Unified management and usually also a unify view of a single logical storage
- Some kind of fault-tolerance or high availability or data protection across the systems
Usually you can consider (to make simple) a scale-in solution like a way to increase only the capacity, but not the number of the storage controllers (and the front-end interfaces), and a scale-out solution like a set of multiple arrays (without shared storage) with a single logical view (but with the power of all of them, both in capacity and in performance).
There real world is, of course, little more complicated and there are also other approaches. There is a great post on the different type of models written by Hans De Leenheer focused on why Windows Scale Out File Server (SOFS) is not exactly a scale-out storage, that explain the full mesh back-end storage architecture.
Effectively the SOFS is scale-out from the front-end point of view, but is limited in scaling from the back-end prospective because the storage must be shared. I don’t mean that is worst or better, just different from a “common” scale-out storage.
For other reason a solution like Dell EqualLogic is not a full scale-out storage solution, because actually it lacks of a distributed data redundancy logic (there is a SyncRep function but failover and failback are just manually, in this version of firmware).
And scale-out storage is evolving from first generations (like Left-Hand was not yet bought by HP) to new generations of scale-out storages with really a huge level of scalability (one of the first in this sense was probably Nutanix) were maybe the new term “Web-Scale” is more appropriate to define those kind of storage.
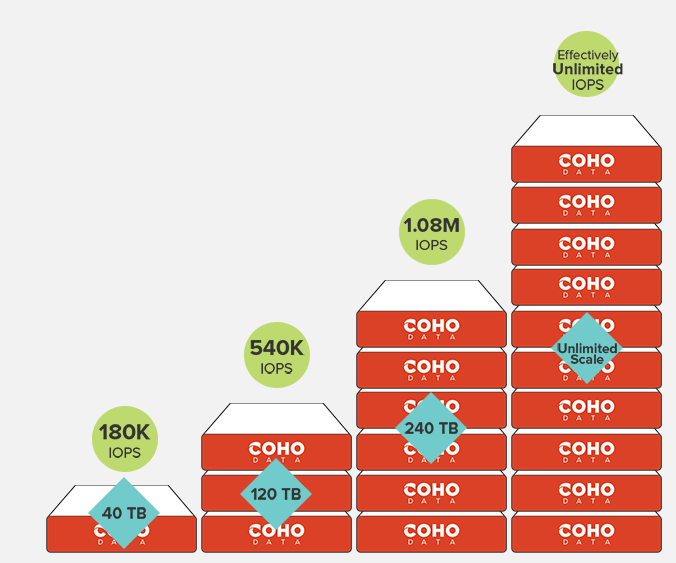
In those cases usually there is no limit (o high limit) and predictable scaling for capacity and performance, like in this example from Coho Data:
Several other scale-out storage vendors (like, for example, SolidFire) bring their point of view for the advantages in a full scale-out solution. But of course is not only black or white. Most storage are going in the scale-out approach (also VSAN, for example), but not all and is interesting see also other point of view.
Pure Storage, for example, reply to some criticisms from XtremIO with this blog post, that contain also some consideration about scale-out vs. scale-in:
Scale-out vs. scale-up is somewhat of an academic discussion, customers should ultimately be asking about the max capacity a given cluster can support, and how much hardware / RUs / cost is required to get there. Pure was designed with a similar Infiniband/RDMA clustered controller interconnect architecture to XtremIO, we’ve just focused first on maximizing vertical scale before horizontal scale (vertical scale is more cost-effective than horizontal scale, horizontal scale becomes important when you need to expand performance beyond what vertical scale can deliver).
Of course is just a point of view but a well designed solution could be valuable independently on his architecture. And architectures are just like fruits: is easy compare apples to pears? Maybe or maybe not. But in some cases we are trying to compare a fruit with a vegetable, that does not make sense at all :)
Anyway some potential advantages of a scale-out (or web-scale) are proved and are not so easy to obtain with a shared-storage architecture: no single point of failure (yes, you can use replication, share JBOD usually does not fail, network could be an issue in a scale-out system, … but remain that a scale-out solution could be potentially more resilient) and the possibility to implement (depending by the software capability) concept like “fault domains” to design a fully reliable infrastructure.
On the other side, a scale-out design must rely on the networking aspect in order to provide communications and network data redundancy and this may limit the scaling opportunity (or introduce more latency in write operation) depending on the design of the storage. From this point of view remain really interesting and actually almost unique the approach of Coho to use both Software Defined Storage (SDS) and Networking (SDN) together in order to build a scalable system.

Related Posts
Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
