

This post is also available in: Inglese
Reading Time: 14 minutesQuesto è il terzo articolo di una serie realizzata per StarWind blog sul tema del design, pianificazione ed implementazione di un’infrastruttura per uno scenario ROBO. L’articolo originale (in inglese) è disponibile a questo link.
Progettare l’infrastruttura per un ufficio remoto
Come descritto, la pianificazione di uno scenario ROBO richiede un progetto in grado di soddisfare le richieste del cliente, in base al tipo di workload. Inoltre deve sia soddisfare requisiti tecnologici (scalabilità, disponibilità, gestibilità, …) ma che sia anche in grado di tenere conto dei possibili rischi.
Logical design di uno scenario ROBO
A seconda dei casi e, soprattutto, a seconda dei workload possiamo avere differenti scenari:
- Nessun server remoto
- Uno o pochi server remoti, che possono fallire (a che quindi non richiedono specifici livelli di HA)
- Alcuni server con requisiti di disponibilità “normale”
- Alcuni server con requisiti di disponibilità elevata
Vediamo di descrivere nel dettaglio ogni caso.
Nessun server remoto
In questo scenario, tutti i server e servizi sono centralizzati nell’ufficio primario (o volendo anche su un public cloud). Ancora più interessante se anche i client sono centralizzati allo stesso mondo usando solutioni di VDI o di RemoteApp, in questo modo, nella sede remota non vi sarebbero né sistemi server né client.
Dal punto di vista della gestibilità, questa soluzioni è la più semplice poiché è tutto centralizzato e quindi facilmente gestibile e monitorabile. Diventa anche un vantaggio dal punto di vista del backup, della data/system protection, del disaster recovery e la disponibilità dei servizi e sistemi è più facilmente controllabile.
Dall’altra parte, in questo scenario, la banda geografica diviene la “rete portante” e l’unico modo che la filiale ha per raggiungere i servizi centrali. Può diventare quindi un grande rischio, dato che può impattare tutti i servizi della filiale. Serve quindi banda adeguata (in base alle postazioni e al tipo di servizi), ma anche una latenza bassa (possibilmente sotto i 100ms) e soprattutto una linea molto affidabile, con pochi problemi di interruzioni che potrebbero rivelarsi frustranti per la user experience e la continuità dei servizi.
Il problema poi si riflette sulla sede centrale (o il punto centrale), che deve avere una banda aggregata sufficiente a reggere tutte le filiali, con le stesse condizioni di latenza e resilienza/affidabilità della linea. Anche per questo può essere interessante una soluzione centralizzata su un provider di public cloud, dato che diventa più semplice ottenere la banda desiderata con l’affidabilità richiesta. Anche una soluzione di hybrid cloud potrebbe risultare interessante.
Ovviamente il tutto con il giusto livello di sicurezza dei dati e delle comunicazioni, quindi con reti dedicate o MPLS o con VPN opportune.
Uno o pochi server (che possono fallire)
Questo è in approccio interessante ma che può funzionare solo nel caso di applicazioni progettate per fallire, e quindi non utilizzabile per tutte quelle applicazioni che invece si aspettano un’infrastruttura sottostante affidabile.
Come discusso nel post precedente, esistono applicazioni in grado di gestire a livello applicativo gli aspetti di alta disponibilità con un fail-over esplicito verso un’altra istanza. In questo caso il fail-over potrebbe essere verso i server centrali e quindi anche nel caso del fallimento dei server periferici i servizi non sarebbero impattati.
Esempi di questo tipo di applicazioni sono:
- Active Directory Domain Controller: un domain controller può fallire, ma il sui servizi possono erogati dagli altri.
- DFS link con servizio FRS: in questo caso uno dei link DFS potrebbe non essere più disponibile (il file server di filiale), ma la risorsa può essere erogata con un link alternativo.
- Caching server (come Branch Cache) o qualunque soluzione di proxy transparente.
Ovviamente tutti questi servizi vanno pianificati attentamente, sia nella topologia (il fail-over deve essere verso il centro e non, per esempio, verso una sede periferica), che nei server di filiale, almeno come risorse minime.
A seconda del numero di workload di filiale richiesti, un solo server fisico potrebbe bastare.
Alcuni server con un livello “normale” di disponibilità
In questo caso viene prevista una ridondanza di risorse tra più server (spesso solo due), ma nessun meccanismo automatico di fail-over. Tipicamente si ha un failover manuale o un semplice service recovery, sempre manuale.
Quello che si cerca di automatizzare è la copia dei dati tra i due ambienti (spesso semplicemente due ambienti con risorse solo locali). Nel caso della virtualizzazione, questa operazione può essere svolta con la replica delle VM, o con la soluzione nativa di VMware (Storage Replica) o con soluzioni di terze parti.
Di fatto ogni nodo è il Disaster Recovery dell’altro e per realtà con grossi limiti di budget può essere una soluzione sufficiente e funzionale e sicuramente più economicamente conveniente della soluzione successiva che richiede uno storage condiviso per l’alta disponibilità.
Alcuni server in alta disponibilità
Se le applicazioni non sono progettate per fallire, l’infrastruttura sottostante deve avere un alto livello di disponibilità, come discusso nel post precedente.
Requisito per l’alta disponibilità delle soluzioni di virtualizzazione è sempre la presenza di uno storage condiviso, ma vedremo che vi sono diversi modalità per arrivare tale risultato.
Physical design
NAS Appliance
In molti casi servirà comunque uno spazio locale per memorizzare file, archivi, backup e la scelta di un NAS economico si rivela naturale.
Questi appliance sono in grado di offrire però molti più servizi di quelli legati alla semplice condivisione di file, si parte dai servizi di base come DHCP, DNS, NTP, … ma in alcuni casi si arriva a vere e proprie app, che includono piattaforme LAMP, Proxy server, motori antivirus, …
Nel caso di applicazioni progettate per essere affidabili, la piattaforma NAS potrebbe persino diventare la piattaforma dove vengono eseguite le VM locali, risparmiando quindi sui costi di un server aggiuntivo.
Ad esempio, Qnap (non nei modelli base) è in grado di eseguire VM locali utilizzando KVM come hypervisor; naturalmente vi sono solo funzioni elementari di virtualizzazione ma più che sufficienti per eseguire un paio di workload che non richiedano un’infrastruttura particolarmente resiliente o prestazione (le prestazioni solo il maggior limite di questi appliance).
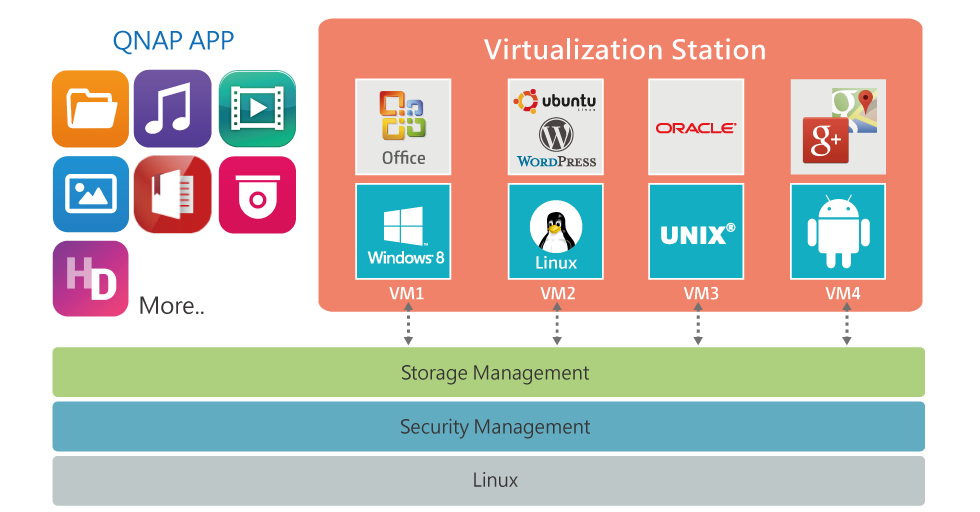
Oltre a Qnap anche altri modelli forniscono funzioni simili. Come pure quasi tutti forniscono funzioni di replica dei file tra appliance (in molti casi si tratta un semplice, ma funzionale, rsync) che può essere comodo per riportare tutti i dati nella sede centrale.
Server fisico
A parte l’esempio precedente e il caso degli uffici remoti senza server, probabilmente avrete bisogno di uno o più (di solito due) server fisici che potranno essere usati direttamente o, più realisticamente, come piattaforma di virtualizzazione. 
Un aspetto importante da considerare per i server ficisi è il form factor. Tipicamente si usano server rack e nel caso ROBO lo spazio potrebbe essere un vincolo. Ma non è detto che la soluzione rack sia la più adatta: in alcuni casi non vi sono armadi adeguati per ospitare server (o per ospitare server moderni abbastanza profondi rispetto a quelli di 10 anni fa). Nel caso non vi sia un armadio rack adatto è più furba la scelta del formato tower che permette una buona flessibilità, a scapito di un maggior spazio utilizzato e un maggior “disordine” nella gestione dei cavi.
Un altro aspetto da considerare è la gestione out of band, molto utile in questi casi e che prende diversi nomi a seconda del vendor (ILOE per HP, iDRAC per Dell, …); si tratta spesso di una licenza in più (o di una componente hardware in più) che puù incidere leggermente sul costo del server, ma che presenta notevoli vantaggi, quali la console remota (rendendo di fatto inutili gli switch KVM) e persino la gestione dell’alimentazione remota (possibilità di accendere, spegnere, resettare il server). Il tutto può enormemente agevolare la gestione centralizzata, visto che poi questi strumenti possono essere integrati in strumenti di gestione e/o monitoraggio.
Per quanto riguarda il dimensionamento del server fisico questi sono gli aspetti da considerare:
- CPU: meglio una soluzione monoprocessore (magari con tanti core) o una soluzione biprocessore? Considerando che molte licenze sono per socket (processore fisico), ma prima scelta potrebbe essere interessante, ma bisogna anche considerare eventuali costi per core (ad esempio il numero massimo da non superare con Windows Server 2016 è di 16 core). Vi sono poi licenze per VM, come il kit ROBO di VMware, in quel caso torna interessante la soluzione biprocessore.
Ma la verità è che raramente il processore è un limite, mentre invece potrebbe esserlo la frequenza operativa: scegliere core con bassa frequenza potrebbe causare problemi ad applicazioni vecchie non disegnate per architetture multi core . Un valore attorno a 2,5 GHz è di solito un buon compromesso. - RAM: bisogna considera che in un cluster a due nodi, ogni nodo deve (nel caso peggiore) sostenere tutti i workload importanti.
Quindi 32 GB di RAM sono il minimo da considerare, anche perché in questo momento i banchi da 16 GB e 32 GB sono i più convenienti (considerando il costo per giga). - Schede di rete: potrebbero servire almeno 4 NIC da 1 Gbps (difficile immaginare i 10 Gbps nelle filiali, almeno per quanto riguarda la parte di networking fisico), ma a seconda del tipo di storage usato, potrebbero servire più schedere di rete.
- Controller di storage: VMware ESXi può essere installato su memorie SD (e molti server hanno configurazioni di SD ridondate) il che permette di avere host completamente diskless, nel caso si usi uno storage esterno, o dischi utilizzabili totalmente per le VM, nel caso di storage locale.
Per altri hypervisor sarà invece necessario prevedere un disco di siste (tipicamente in RAID1 o un disco logico di un aggredato RAID differente).
Per soluzioni di storage iperconvergente, il tipo di controller e la sua configurazione potrebbero essere fondamentali per le prestazioni e la resilienza del sistema. - Dischi locali: necessari nel caso di soluzioni standalone o soluzioni iperconvergenti (per queste si rimanda al posto successivo).
- Schede SAS: vi potrebbero essere altre periferiche non di tipo disco, come ad esempio le unità tape (per avere un backup locale). Scegliere una scheda dedicata permette di utilizzare su VMware la funzione di DirectPath (PCI pass-thought) utile per implementare il server di backup (o il media server) in virtuale con comunque prestazioni vicine a quelle native e riducendo il numero di server fisici.
Ci sono poi da considerare gli alimentatori, ma per lo scenario ROBO due alimentatori a media potenza vanno più che bene. Anzi è meglio avere alimentatori con cavi standard in modo da non richiedere impianti elettrici a doc. Aspettatevi (su server moderni) un consumo attorno ai 150W per server biprocessori e attorno ai 120W per sistemi monoprocessore.
Oltre ai consumi ridotti, un aspetto interessante dei nuovi server è la possibilità di usare il fresh air cooling: invece che far funzionare i server in ghiacciaie, questi nuovi server possono funzionare anche a temperature più elevate, in alcuni casi fino 45°C di picco e attorno ai 29°C di temperatura ambiente. Aspetto da non sottovalutare in un’ottica di ottimizzazione dei costi operativi.
Storage
Per la parte di storage vi sono diversi scenari possibili:
- Solo storage locale e non condiviso tra gli host: in questo caso non si possono usare funzioni di alta disponibilità, ma per alcuni casi potrebbe andare bene limitarsi ad una semplice replica delle VM e una procedura manuale per l’attivazione delle stesse. Certo i requisiti di RPO e RTO non possono essere stringenti.
Notare che sia VMware vSphere (a partire da vSphere 5.1) che Microsoft Hyper-V (a partire da Windows Server 2012) forniscono una replica delle VM nativa..
C’è poi da considerare che sia con vSphere che con Hyper-V è possibile, nel caso di attività pianificate, spostare a caldo le VM tra un host ed un altro anche senza storage condiviso. - Storage locale, ma con una soluzione iperconvergente: questo caso sarà discusso nel prossimo post.
- Storage esterno: esistono sicuramente soluzioni di storage esterno economiche (gli stessi appliance NAS descritti in precedenza, spesso sono compatibili per questo utilizzo), ma il livello di disponibilità (e prestazioni) potrebbe essere basso.
Servirebbe una soluzione SAS, iSCSI o FC (anche se la più ragionevole è la soluzione SAS, se non altro per eliminare il costo di switch dedicati e la complessità della parte di rete) con un controller ridondato. Moltre di queste soluzioni sono in grado di gestire anche tipi di dischi diversi tra di loro.
L’unica vera limitazione delle soluzioni SAS è la scalabilità dei nodi, ma spesso arrivano fino a 4 nodi, più che sufficienti per lo scenario ROBO! - NAS: come scritto in precedenza questa soluzione di storage esterno non è adatta per questioni di disponibilità e prestazioni (nel caso dei NAS economici) o potrebbe essere troppo costosa per soluzioni di tipo enterprise.
Per quanto riguarda il tipo di dischi, attualmente le soluzioni SSD sono diventate più convenienti rispetto ai dischi tradizionali da 15k, ma ancora più costose rispetto a dischi da 10k o Near-Line. Il tipo e il numero di dischi dipende fortemente da tipo di workload che si prevede di utilizzare.
Soluzioni convergenti
Le soluzioni convergenti integrano storage, rete e risorse di computing in un singolo chassis e più risorse si possono aggiungere mediante opportuni moduli o lame. In questa categoria rientrano le soluzioni blade che però sono sovradimensionate rispetto allo scenario ROBO.
Molto interessante invece il Dell PowerEdge VRTX che è invece molto adatto al caso ROBO, dato che è in grado di ospitare fino a 4 nodi server, tanti dischi condivisibili (fino a 25 usando il form factor da 2,5” o fino a 12 usando quello a 3.5”). Può persino includere uno switch integrato a 1Gbps o 10 Gbps. Il tutto in furmato tower (o volendo anche in formato rack da 5U).
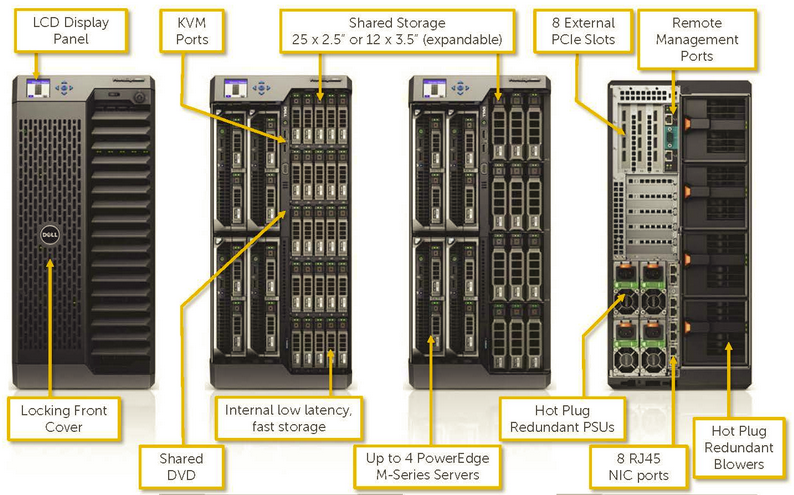
Il “blocco” ideale per costruire la parte infrastrutturale per ogni filiale e con molte funzioni software di gestione, come ad esempio la gestione e monitoraggio centralizzato (inclusa la vista geografica).
Ma potrebbe costare di più della soluzione successiva e deve essere comunque progettato con l’opportuna ridondanza (ad esempio lo switch interno non ha ridondanza e bisogna quindi aggiungere schede PCI di rete aggiuntive per usare un secondo switch esterno).
Soluzioni iperconvergenti
Le soluzioni di tipo HCI (Hyper-Converged Infrastructure) rappresentano un interessante trend nel mondo dello storage e della virtualizzazione.
Utilizzando server standard sia per la parte di calcolo che per la parte di storage è possibile semplificare la soluzione infrastrutturale e scalarla in modo flessibile. Il tutto senza perdere dei vantaggi funzionali di una soluzione di storage condiviso (di fatto gli storage locali vengono trasformati in uno storage condiviso).
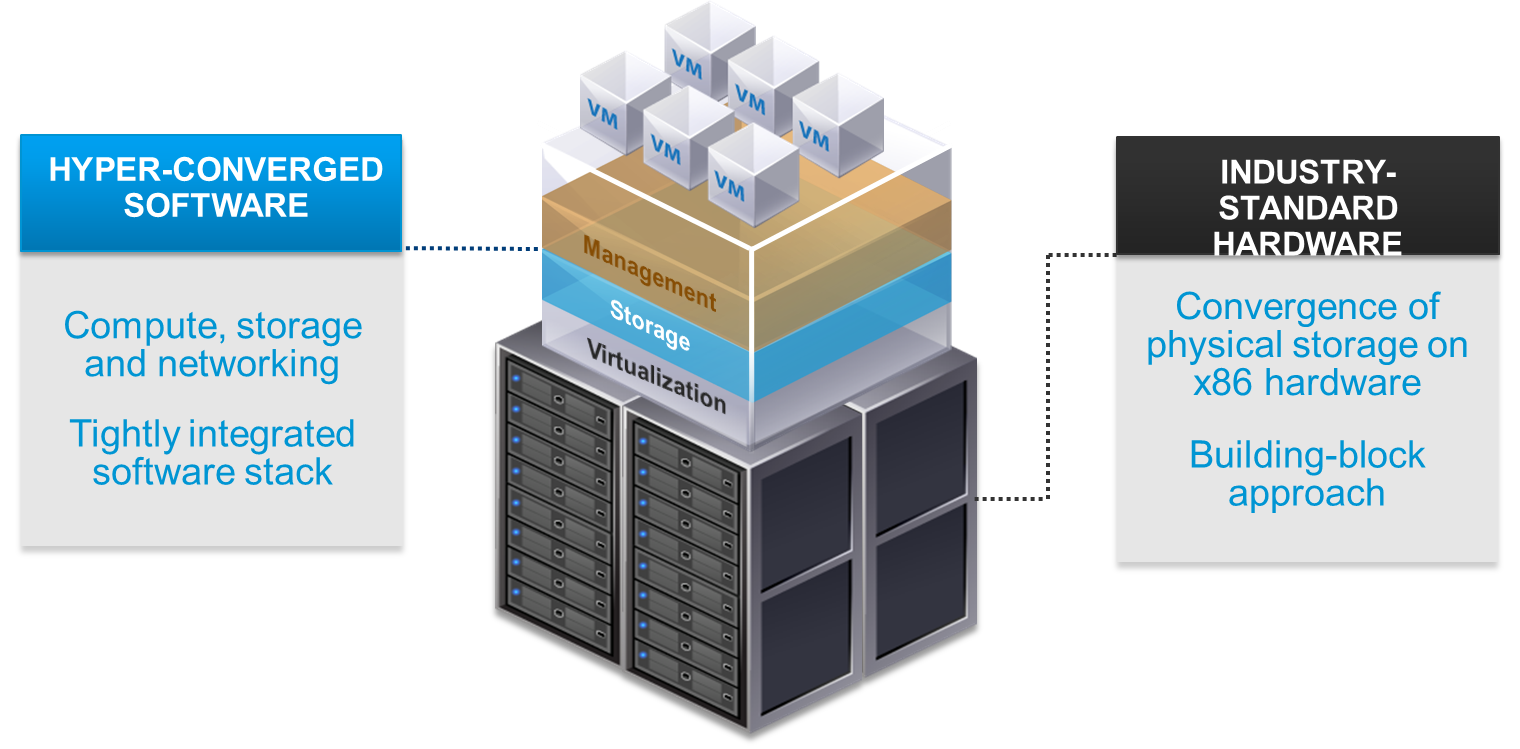
Questo soluzioni scalano tipicamente da 2 o 3 node in su, a seconda della tecnologia e del prodotto:
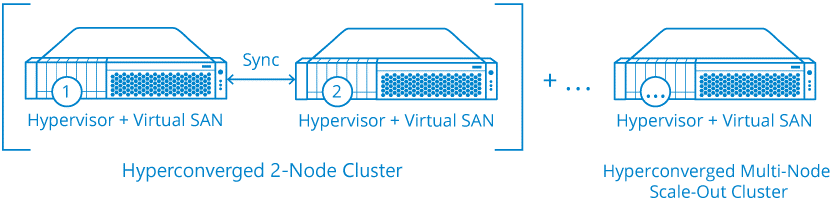
Ma per lo scenario ROBO il caso più interessante è la configurazione a due nodi, che rende molte soluzioni iperconvergenti non utilizzabili (tutte quelle che richiedono almeno 3 nodi per partire).
Nel prossimo post vedremo in maggior dettaglio le soluzioni iperconvergenti a 2 nodi.
Vedere anche:
- Design a ROBO (Part 1): Introduction and high-level design
- Design a ROBO infrastructure (Part 2): Design areas and technologies

Related Posts

Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
