








The mitigations for Meltdown and Spectre issues have involved a combination of different type of fixes: some software based, such as Microsoft and Linux versions of the “kernel page table isolation” protection, but also fome hardware based, like the Intel’s microcode updates (part that is still missing in most cases).
Both type of patches can cause performance overheads and have some kind of impact on your environment. But how can you estimate it (before apply the patches) and how can you measure it (when the patches have been applied)?
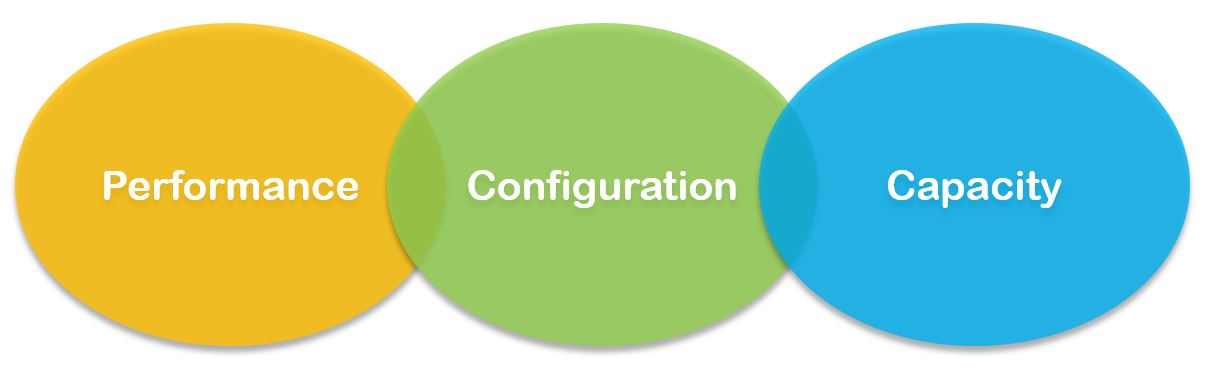
You must track the following key areas of your environment: performance, configuration and capacity.
Estimate the performance impact
A good resources and capacity assessment could be really crucial before apply any patches on a large environment, both due to the performance impact of Meltdown and Spectre patches (you can consider a potential 10% of degration, but the worste case could be 20-30%!), but also because when you are applying the patches there will be a temportally reduction on the host resources, due to the maintanance activities.
With a good assessment, you can verify if there are enough resource, but also identify if there are some inefficiencies of wasted resources that can be released to provide more capacity.
Turbonomic includes modelling and planning features within your environment to accurately measure the impact of changes to utilization and performance, including how to optimize in light of those changes. There is an interesting post (Mitigating the Meltdown and Spectre Patch Performance) that provide several details on how using the out-of-the-box planning features to creating a custom plan allows you to add a simulated percentage of load to the environment.
You can choose to assess this on any subset of the environment as well, so it may be able to be done at the host, cluster, data center, or any scope within the environment.
The first step is estimate the performance impact: also if you select a conservative percentage may still produce results which may surprise you with the impact it can have on the environment.
![turbonomic-plan-load-percentage-7[1]](https://cdn.turbonomic.com/wp-content/uploads/turbonomic-plan-load-percentage-71.png)
Once you know the impact, Turbonomic can help you mitigate part of it, using some specific functions:
- Auto-placement: Turbonomic choose the right place to run your workloads in order to meet the real-time demand, including host-level CPU queueing challenges and much, much more
- Auto-scaling: scale up, down, or out, depending on the workload profile, all powered by the intelligent decision-engine
- Create superclusters: leverage the hardware pool by expanding workload reach across clusters to better utilize the underlying infrastructure
- Reduce performance bottlenecks: storage latency, network latency, application QoS and much more can be proactively affected by Turbonomic to deliver better workload and infrastructure performance
Also VMware has realize an interesting post on how perform an assessment (Assess performance impact of Spectre and Meltdown patches using vRealize Operations Manager)
With vRealize Operations you have six dashboards and features to help you assess your environment.The usuage is quite similar on each resource and capaty assessment.
For example, to look for changes in CPU and Memory Usage per cluster using the Capacity Overview dashboard:

Or to look for reclaimable resources with Capacity Reclaimable dashboard:

But there is also a “seventh dashboard”, that is a kit of three custom dashboards from VMware developers that you can download and use if you have the vRealize Operations Advanced or Enterprise Editions. This is a small library of three custom dashboards that focus on the configuration, performance, capacity, and utilization of your virtual infrastructure. Here is what you will get after the import:

The dashboards include:
- Performance Monitoring
- Planning Guest OS Patching
- Tracking vSphere Patching
How do you can get the custom dashboard kit? Download it from this link along with the instructions on how to import them.
Measure the performance impact
As a result of the proposed “fix” for these vulnerabilities, there is high potential for an impact on performance. TechCrunch covered this, writing: “The Meltdown fix may reduce the performance of Intel chips by as little as 5 percent or as much as 30 — but there will be some hit. Whatever it is, it’s better than the alternative.”
The problem is that the real performance degradation is hard to be estimated, because can really vary on how the patches are built (see for example how the latest Linux kernel can improve this aspect) but also on your workload types, because the impact of these patches will vary for each use case and application.
This explain why some vendors have not report yet any data, for example VMware is still evaluating the performance costs of the Meltdown/Spectre mitigations for VMware products. For more information see VMware KB 52337.
The best way is use an holistic approach and measure by yourself.
VMware has realized an interesting post (Understanding the impact of Spectre and Meltdown patches for end users and consumers) on how use Log Insight and Wave Front to understand what the impact is on applications as well.
The post describe a method, starting with a baseline system, that is any system that is currently unpatched. Once we have that we can compare that baseline to a newly patched system. All with a nice example for measing the performance on a web server (IIS based), and how visualize pre-patches data and post-patches within interactive analytics:



