








PernixData FVP è un software di tipo Flash Hypervisor (pensato e progettato per il mondo VMware vSphere) in grado di aggregare server flash in un cluster scalabile (di tipo scale-out) con funzioni di data tier per accelerare le letture, ma anche le scritture rendendo più veloce lo storage condiviso esistente. Questa soluzione è stata una delle prime (se non la prima in assoluto) ad implementare una fault-tolerant write back usando flash locali.
Nei post precedenti sono state descritte le fasi relative all’installazione e alla configurazione ed utilizzo di FVP 1.5 su vSphere 5.5; quest’ultimo post della serie sarà dedicato alle conclusioni ed osservazioni su questo prodotto innovativo.
Partiamo dalle considerazioni riguardo i miglioramenti ottenibili da una soluzione come questa. All’inizio pensavo di riportare direttamente dei numeri nudi e crudi, ma in realtà sto ancora lavorando nell’individuare un insieme decente di tool di analisi delle prestazioni in ambiente virtuale; esistono tanti strumenti, ma i dati ottenibili sono spesso troppo variabili e l’ambiente virtuale in generale non è poi così semplice da misurare.
Ancora più complicato poi se vogliamo misurare il vantaggio apportato da una soluzione di host cache dato che ottenere dati congrui e ripetibili con test di benchmark puro diventa ancora più difficile (a seconda che il dato si trovi o no nella cache!). Oltretutto le cache hanno bisogno di tempo per popolarsi ed iniziare ad apportare benefici.
Sul sito di PernixData sono riportati i seguenti numeri:
- Accelera le prestazioni delle applicazioni: migliora le prestazioni di lettura e scrittura di applicazioni I/O intensitive fino a 10 volte in media (portando la latenza da millisecondi a microsecondi).
- Posticipa la necessità di uno storage refresh: PernixData FVP è grado di fornire IOPS fino a 62 volte maggiori ad 1/6 del costo nel caso di nuove unità SAS, oppure 32 volta ad 1/3 del costo nel caso di soluzioni SSD.
- Ottenere il meglio dai nuovi storage array: è possibile ottenere un ulteriore 6x di IOPS anche dai nuovi array ibridi, riducendo al contempo il costo l’investimento in questa tecnologia di 1/2.
- Proiettato verso il futuro: le prestazioni di storage in grado di scalare in modo lineare e con approccio scale-out riduce al minimo i costi e massimizzare le prestazioni delle applicazioni (di oggi e domani).
Ma tutte queste affermazioni sono vere o almeno si avvicinano alla realtà?
Come scritto in precedenza, non è semplice condurre un’analisi delle prestazioni con puri strumenti di benchmark del disco: i valori iniziali sarebbero non accelerati e solo dopo varie ripetizioni si inizia a vedere valori ragionevoli che in effetti si avvicinano al fattore moltiplicativo di 10 dichiarato da PernixData.
Peggio ancora misurare gli IOPS e il relativo miglioramento. Diventa molto più sensato individuare delle applicazioni e testare quelle in modo magari soggettivo ed empirico, ma guardano a quando possono scalare. Nel mio caso ho condotto un semplice test, accelerando un datastore SATA (composto da soli 2 dischi SATA in RAID1 su un vecchio storage iSCSI Dell PowerVault MD3000i) e devo dire di essere stato sorpreso di quando potesse scalare abilitando la cache write back (nei test l’ho utilizzata senza ridondanza, per non sovraccaricare i link di rete): senza cache già con 3-4 virtual desktop le prestazioni degradano vistosamente (con latenze che iniziano a crescere rapidamente), ma con la cache (attenzione a come vengono accelerati i linked clone, come spiegato di seguito) si possono ottenere risultati interessanti e un consolidamento decisamente migliore (sono arrivato a più 20 virtual desktop con prestazioni molto buone. Esistono anche altri post con test simili, ad esempio (in inglese): PernixData FVP accelerate your Horizon View deployment.
Quello che è certamente un beneficio della host cache è la capacità di ridurre sia l’uso della banda nei link di front-end dello storage sia la “pressione” sulla cache all’interno dello storage, alleggerendo il lavoro dello storage e lasciando più risorse libere (queste informazioni, sia in termini di IOPS e banda salvati, sono disponibili nelle informazioni riportate a livello di flash cluster overview).
Riguardo al costo ed al possibile risparmio, sono numberi già un po’ più contenstabili. Vanno considerate le licenze di FVP, ma anche i costi delle flash locali (per avere write back tutti i nodi del cluster devono avere almeno una flash locale). Volendo è possibile usare flash diverse sui vari nodi, come riportato in questo schema, ma sinceramente mi sembra solo un modo per aumentare la variabilità e rendere meno deterministico il sistema finale (si potrebbero ottenere prestazioni diverse tra i vari nodi).
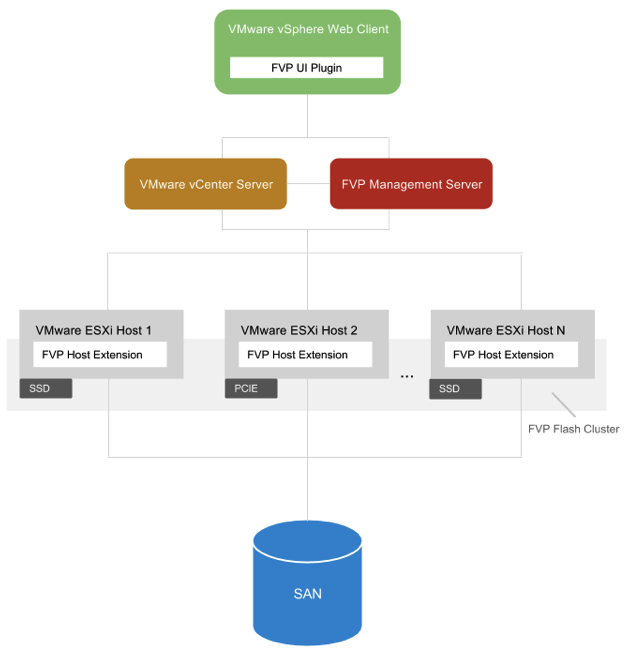
Va inoltre considerata la rete per la replica tra le cache: dato che è sincrona la rete deve essere ad alta velocità (l’ideale è avere link a 10Gbps) per non penalizzare la latenza delle scritture. Ma anche qua va pianificata e c’è da prevedere anche questo costo aggiuntivo.
Ovviamente anche il throughput della flash deve essere considerato, ma probabilmente tra una cache molto veloce e una cache leggermente meno veloce ma più grande l’ago si sposta normalmente verso la seconda opzione. Non ho avuto tempo e modo (il controller locale non forniva funzioni di pass-though decenti) di verificare quale fosse la differenza tra l’uso di schede PCIe (le Fusion-IO nel mio caso) e l’uso di dischi SSD locali. In linea di massima se il costo è il primo aspetto da considerare la scelta sarà abbastanza forzata sulla seconda opzione.
Quindi è tutto così bello? Beh… qualche limite c’è e va considerato. In generale le soluzioni di tipo host cache non solo una panacea per tutti mali degli storage; dipende anche dal tipo di workload che avete… ma il discorso è ben più ampio e merita sicuramente un approfondimento a parte.
Vi sono poi alcune considerazioni specifiche per quanto riguarda FVP:
- Lavora solo VMware vSphere 5.x: sicuramente è un limite per chi cerca ambienti multi-hypervisor o con altri hypersor, ma in realtà per chi usa VMware è un grande vantaggio visto che funziona su tutte le versioni vSphere 5.x e che soprattutto non richiede per forza l’edizione Enterprise Plus di vSphere 5.5 (come ad esempio la soluzione di host cache di VMware, che comunque è anche limitata solo per le operazioni di lettura).
- I template, le ISO e le VM spente non vengono accelerate: quindi operazioni come deploy da un template o il clone di una VM spenta non hanno un beneficio. Questo porta anche ad un potenziale limite negli scenari di View, dato che la VM di base dei linked clone è una VM spenta e quindi non accelerata. Questa deve essere salvata su uno storage sufficientemente veloce in lettura.
- Come scritto nel post precedente, i dischi flash utilizzati da FVP non sono marcati come in uso: si corre quindi il rischio di formattarli come nuovo datastore.
- A seconda della licenza di FVP potete usare solo una flash per host o più di una: questo potrebbe essere molto interessante per implementare Flash Cluster multipli con diverse policy di cache.
- Trovo l’attivazione delle licenze un’operazione un po’ complicata: quella online richiede l’uso di programmi Java da installare localemente, quella offline è lineare, ma decisamente non immediata.
- Al momento, con la versione 1.5 (ma leggete le note sulla novità della prossima versione) funziona solo con datastore a blocchi e non con datastore NFS:

- FVP è compatibile con la maggior parte delle funzioni di vSphere, ma sinceramente qualche problemino (come descritto nei post precedenti) l’ho avuto specialmente con lo Storage vMotion e con DPM. Sarebbe utile un buon documento sulla CLI di FVP che dovrebbe essere in grado di sistemare le possibili inconsistenze che si creano in casi molto particolari (in questi casi tipicamente la cache viene disattivata su singole VM o persino di datastore).
- Per accelerare le scrittture con il write back è necessario che tutti i nodi ESXi abbiano una cache locale (per accelerare solo le letture questo vincolo non sussiste): questo è un limite noto, ma è importante notare che i casi di manutenzione programmata dei nodi o di VMware HA sono gestiti correttamente dal Flash Cluster in generale senza disattivare il write back.
Novità della prossima versione
Giovedì 24 aprile, durante la quinta edizione dello Storage Field Day (#SFD5), PernixData ha annunciato ufficialmente le novità delle prossime versioni: PernixData Introduces New FVP Features to Accelerate any VM, on any Host, with any Shared Storage System.
Ulteriori informazioni sono disponibili (sempre in inglese) anche in un post di Duncan Epping (PernixData feature announcements during Storage Field Day); ma le novità principali sono sintetizzabili in questi punti:
- Supporto per datastore NFS
- Network Compression
- Distributed Fault Tolerant Memory
- Topology Awareness
Sarà quindi molto interessante provare la nuova versione e sicuramente meriterà post di approfondimento. A meno di grandi novità da parte dei competitor, potrebbe diventare una vera a propria killer-application in questo settore.
Vi sono anche novità interessanti per quanto riguarda l’Italia. La prima è che PernixData ha siglato un accordo di distribuzione con SYSTEMATIKA e quindi diventa finalmente disponibile anche nei listini italiani.
La seconda è che PernixData è presente come sponsor alla prossima VMUG.IT User Conference (prevista il per 7 maggio). Un’occasione in più per partecipare a questo importante evento.

Andrea Mauro
Virtualization, Cloud and Storage Architect. Tech Field delegate. VMUG IT Co-Founder and board member. VMware VMTN Moderator and vExpert 2010-24. Dell TechCenter Rockstar 2014-15. Microsoft MVP 2014-16. Veeam Vanguard 2015-23. Nutanix NTC 2014-20. Several certifications including: VCDX-DCV, VCP-DCV/DT/Cloud, VCAP-DCA/DCD/CIA/CID/DTA/DTD, MCSA, MCSE, MCITP, CCA, NPP.
