








Qualche mese fa Rubrik aveva annunciato la disponibilità della versione 2.0 della loro soluzione Rubrik Converged Data Management orientata ad un nuovo approccio alla data protection (vedere anche il mio post precedente).
Rubrik è la classica start-up americana nel mondo dello storage (anche se è riduttivo classificarla in questa area specifica), con un prodotto interessante, ma soprattutto un approccio abbastanza innovativo.
La novità (in realtà non di Rubrik, ma è un vero e proprio trend recente del mercato) è nel modello utilizzato per risolvere il problema dei backup e in generale quella della data protection.
Negli approcci “tradizionali” (incomincia a diventare improprio parlare di tradizionale, visto che il backup ha visto negli ultimi 10 anni la nascita di sistemi di backup nativi per il mondo della virtualizzazione) l’architettura può essere composta da tanti componenti:
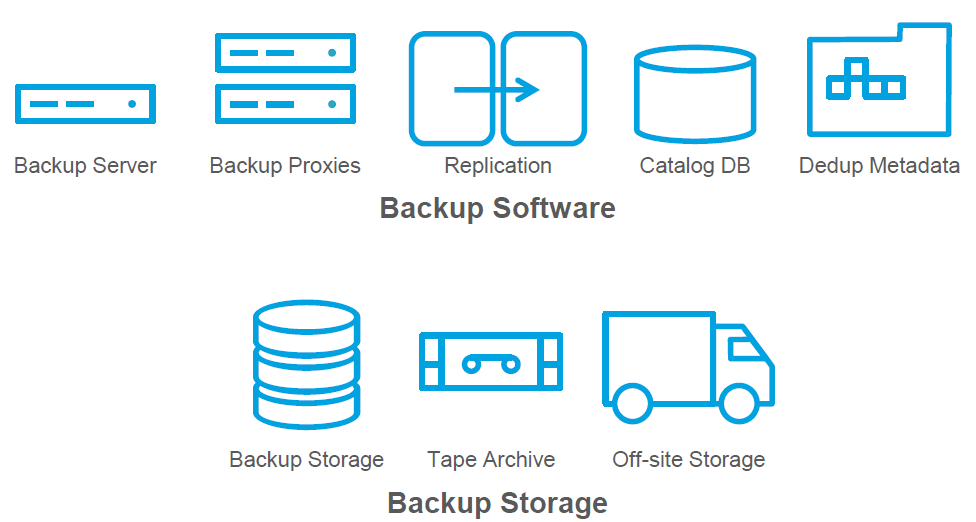
L’idea di Rubrik è quella di eliminare tutte queste componenti:
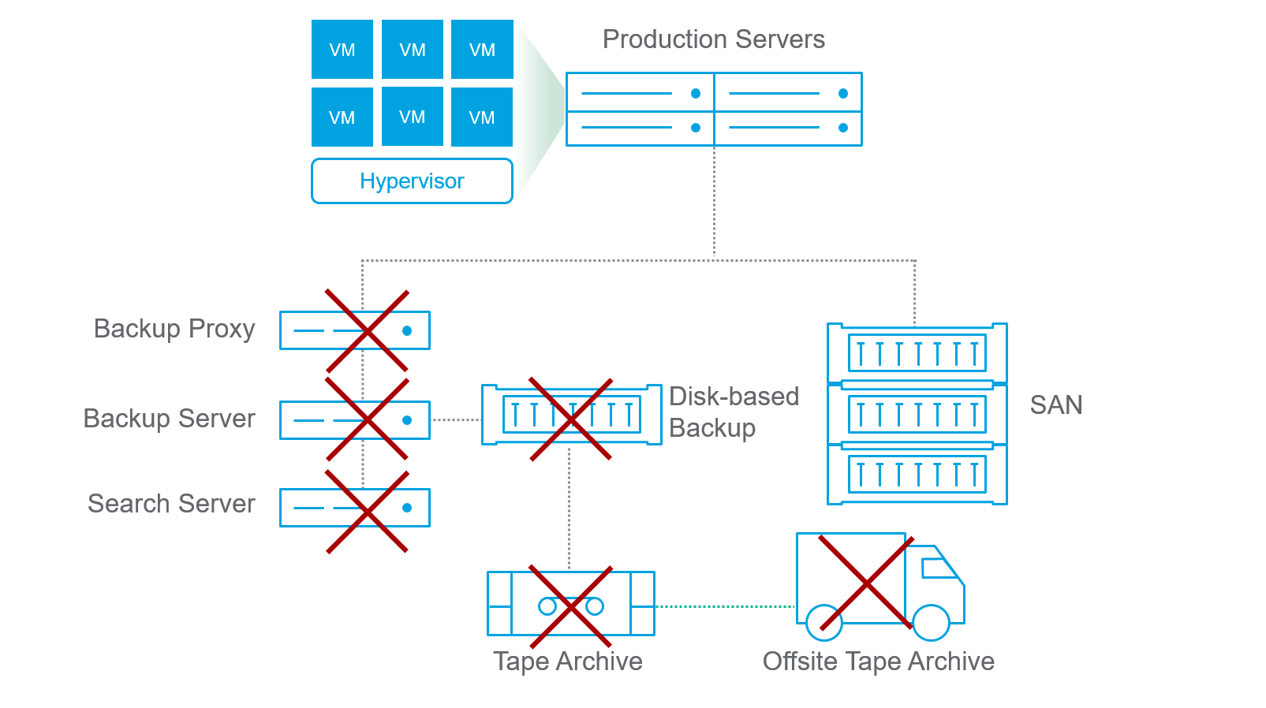 Ed inglobarle in un’unica soluzione:
Ed inglobarle in un’unica soluzione:
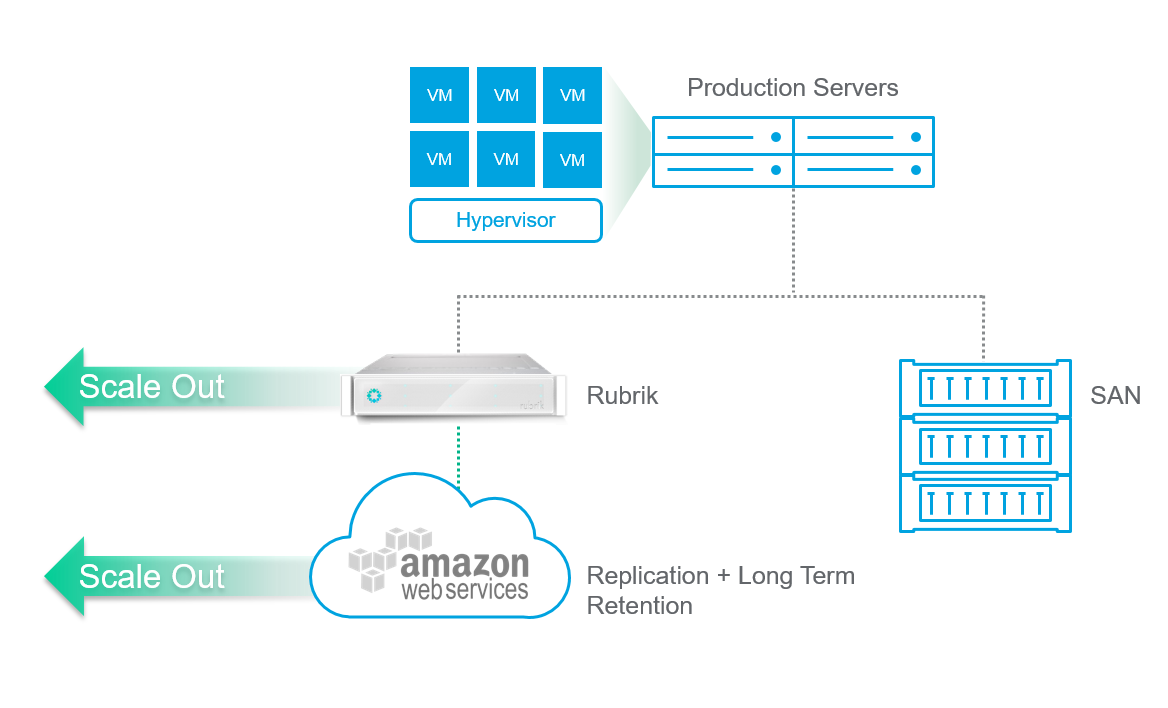 L’idea è simile a quella di Cohesity (per fare un esempio, ma come detto è un nuovo trend che incomincia a diffondersi), ma Rubrik punta direttamente alla data protection come caso d’uso principale (a differenza di Cohesity che prevede tanti altri possibili utilizzi), risultando quindi qualche passo avanti in questo specifico caso.
L’idea è simile a quella di Cohesity (per fare un esempio, ma come detto è un nuovo trend che incomincia a diffondersi), ma Rubrik punta direttamente alla data protection come caso d’uso principale (a differenza di Cohesity che prevede tanti altri possibili utilizzi), risultando quindi qualche passo avanti in questo specifico caso.
Molto curioso notare come tra i vari investitori vi siano anche persone di Symantec, Data Domain, Veritas! Qualcuno sicuramente ci crede in questo approccio.
Durante l’ultimo IT Press Tour #17 ho avuto modo di conoscere meglio il prodotto direttamente dalle persone del board di Rubrik: Bipul Sinha (CEO), Arvind Jain, Arvind Nithrakashyap. Per la parte tecnica c’era anche Chris Wahl (mia vecchia conoscenza dai tempi della certificazione VCDX).
La soluzione è quindi costrita attorno (o più correttamente dovremmo dire “dentro”) un appliance (fisico), scalabile secondo un modello scale-out, o, come dicono in Rubrik (ma anche in Nutanix), “Web-Scale” tipico del mondo iper-convergente. In effetti si tratta proprio di una soluzione hyper-converged per storage e servizi di secondo livello (ipotizzando il primo quello dello storage in produzione). Si parte da un minimo di 3 nodi (tipico per questo tipo di prodotti) e si scala quando serve di un appliance alla volta.
La serie r300 del Converged Data Management Appliance prevede nodi da 2U con 12x4TB HDD oppure 12x8TB HDD, con 4x400GB SSD. L’intera deduplica è cluster-wide.
Tipica di queste soluzioni è anche la semplicità d’uso: il sistema può essere up and running in 15 minuti! Bipul Sinha sintetizza in modo efficace il concetto: “it looks simple because we make it simple”!
Al momento supportano VMware vSphere 5.1, 5.5 o 6.0 e tutto quello che serve è puntare ad un vCenter Server e creare le relative policy di backup (chiamate SLA Domains) per proteggere le VM secondo le vostre classificazioni. Al fine di garantire una maggior consistenza, viene automaticamente iniettato un VSS provider in ciascuna VM (Windows) protetta.
Anche se per ora l’unica piattaforma supportata è quella VMware, l’intera soluzione è platform agnostic, ed è quindi pensabile (ed auspicable) vedere in futuro altri hypervisor supportati (anche se vedo alcune difficoltà nell’implementare una soluzione agent-less per Hyper-V con questo approccio, per il tipo di sistema operativo presente nei vari appliance). Il caso fisico al momento non sembra invece di interesse.
Al fine di avere una replica remota o semplicemente una retention di lungo periodo e a basso costo, sono supportati object storage esterni: Amazon S3 per soluzioni di public cloud, oppure S3 (ad esempio con Scality) o Swift per soluzioni on-prem. In teoria anche NFS potrebbe essere utilizzato per soluzioni on-prem come target per backup.
Per quando riguarda la replica remota, Amazon S3 è solo una delle opzioni, ovviamente è possibile combinare tra loro più cluster Rubrik in replica asincrona, tipicamente in logica DR.
Sarà sicuramente interessante vedere come queste soluzioni di tipi “convergente” possano o meno diffondersi, in parte a scapito di altre soluzioni già esistenti. Certo anche le soluzioni esistenti possono evolversi verso soluzioni appliance based (in fondo dai primi modelli di Data Domain, qualcosa è effettivamente cambiato nell’approccio ai backup), ma non sempre è facile o conveniente o efficace (ad esempio, Veeam, anche con lo Scale-Out Repository della nuova versione, non sarebbe una soluzione comparabile in termini di architettura a quella di Rubrik o Cohesity).
Dall’altra parte i software di backup specializzati sono anni avanti in alcune funzioni di alto livello: si pensi ad esempio all’application-level recovery? Rubrik al momento non prevede nulla, se non tramite una partnership con Kroll on Track.
Disclaimer: Sono stato invitato a questo evento da Condor Consulting Group che ha coperto i costi per il viaggio e l’alloggio. Ma non sono stato ricompensato in alcun modo per il mio tempo e non sono in obbligo di scrivere articoli riguardo all’evento stesso e/o gli sponsor. In ogni caso, i contenuti di questi articoli non sono stati concordati, rivisti o approvati dalle aziende menzionate o da altri al di fuori del sottoscritto.

